Model Review
Code Review is an integral part of software development, but many teams across industry don’t have similar processes in place for the development and deployment of Machine Learning (ML) models.
In this post, I’ll share how adopting a model review step pre-deployment has greatly benefited our Cash ML team by:
- Providing transparency for how production models were trained and their expected performance.
- Increasing reproducibility, so models can easily be retrained or debugged.
- Giving a platform for knowledge sharing of ML approaches and tools among teammates.
Motivation: why do we review models at Cash App?
When I joined Cash App, my team had recently doubled in size, and was deploying more and more models. But we only had scattered and inconsistent record keeping of what models exactly were in production, how they had been trained, and what kinds of approaches or techniques were working well for us. We started to ask questions like
- how can we retrain an existing model?
- how can we get new team members up to speed and have them build off work that has been done by others?
- what was the precision on this model supposed to be, anyway?
The answer to all of these questions was inevitably
Let me see if I can find that notebook…
The notebook in question was typically found (with some effort). But, as many readers will know, Jupyter Notebooks are not a foolproof way to record anything programmatic, since there is no guarantee that the cells were actually run in order and the contents of them haven’t changed.
We decided we needed a better system in place, one that would help us achieve transparency in what is actually being deployed, reproducibility of past experiments and ease of building off them, and a better way to share knowledge among teammates. We had another requirement too: we needed to automate as much of this new process as possible. We didn’t want to add a bunch of manual overhead to our model lifecycle.
Code vs Model Review: the same but different!
Why do we review code? More eyes helps to spot bugs or other issues. The process of a pull request allows teammates to learn from each other’s approaches, and it creates a record of changes and (ideally) also documentation of decisions and trade-offs that were considered in the design. These are all things we might hope to achieve when reviewing a model.
Similar to a code review, with an ML model there is code involved (your training script or notebook). But that is where the similarities pretty much end, because there is a lot of context that is not obvious from the training code, yet is really important to getting a comprehensive understanding of a model:
- data, including any transformations
- model performance on key metrics
- the entire modeling process
Let’s talk about that last bullet point for a minute. You don’t just write up some training code and train one model, right? You might have simple baseline models that you trained first and are trying to beat. You likely have a ton of unsuccessful training results. Maybe you did hyperparameter tuning, and you compared results across these different runs. Perhaps you tried some different label definitions or unconventional data processing. This is all important context for another person to understand the “final” model that has been deemed ready for deployment.
So, for all the reasons above, we can’t really review a model just by looking at the final code that produced it.
MLflow: a great tool for Model Review!
MLflow is an “open source platform for managing the end-to-end machine learning lifecycle”. It consists of several distinct products that can be used separately, but also work nicely together (Tracking, Projects, Models, and Model Registry). We’re going to focus here just on the MLflow Tracking component, which allows you to easily log basically anything you’d want to keep track of:
- parameters
- metrics
- arbitrary files (“artifacts” in mlflow) such as plots, text files, Jupyter notebooks…
- code version
- training data
MLflow works hard to be language and ML library agnostic, so while my particular team uses it with Python and Tensorflow, it would almost certainly be compatible with your tech stack as well.
Getting Started with MLflow Tracking
As a basic starting point, one can explicitly track each value, file, model, etc:
import mlflow
# a context manager encapsulates all tracking commands within the same "run"
with mlflow.start_run(run_name='useful-description'):
mlflow.log_param('important_parameter', 3)
mlflow.log_metric('score', 95)
mlflow.log_artifact('some_file.txt')
mlflow.sklearn.log_model(model, 'my_trained_model')
A really awesome feature of MLflow is the ability to autolog details of your modeling, without explicitly adding tracking commands for each of them.
Including just a single line of code, e.g. mlflow.autolog(), will automatically track all model parameters (even those you did not explicitly set), the trained model, metrics, and (depending on the type of model) some useful plots like confusion matrices and precision-recall curves.
It’s pretty slick.
Here is a more fleshed out toy example that classifies (TF-IDF transformed) text as being about hockey vs baseball:
import mlflow
import tensorflow as tf
from tensorflow.keras import Input, Model, layers
# parameters to vary
hidden_layer_size = 32
learning_rate = 0.01
with mlflow.start_run(run_name=f'sports-NN-{hidden_layer_size}d-lr{learning_rate}'):
mlflow.tensorflow.autolog() # just one line added!
# a simple NN with one hidden layer
inputs = Input(shape=(X_train.shape[1],))
x = layers.Dense(hidden_layer_size, activation='relu')(inputs)
outputs = layers.Dense(1, activation='sigmoid')(x)
model = Model(inputs, outputs)
loss = 'binary_crossentropy'
optimizer = tf.optimizers.SGD(learning_rate=learning_rate)
metrics = [
tf.metrics.BinaryAccuracy(),
tf.metrics.AUC(curve='ROC', name='AUROC'),
]
model.compile(optimizer=optimizer, loss=loss, metrics=metrics)
model.fit(X_train, y_train, epochs=40, shuffle=True, validation_data=(X_test, y_test))
If you’d like to see the data loading and processing used above, and for more examples, you can check out the full Jupyter Notebook presentation code on GitHub.
Viewing & Sharing Results
What makes MLflow so useful to our team, is the fact that the logs are displayed in a really nice UI (see the docs for different ways to set up the Tracking UI). We can send each other URL links to MLflow Runs, and see all the details about how the model was trained and what its offline performance was. For the hockey-vs-baseball classifier above, the MLflow Run looks like this in the UI:
![]()
Notice all the parameters, metrics and artifacts that are tracked here, all by simply adding that single mlflow command for autologging.
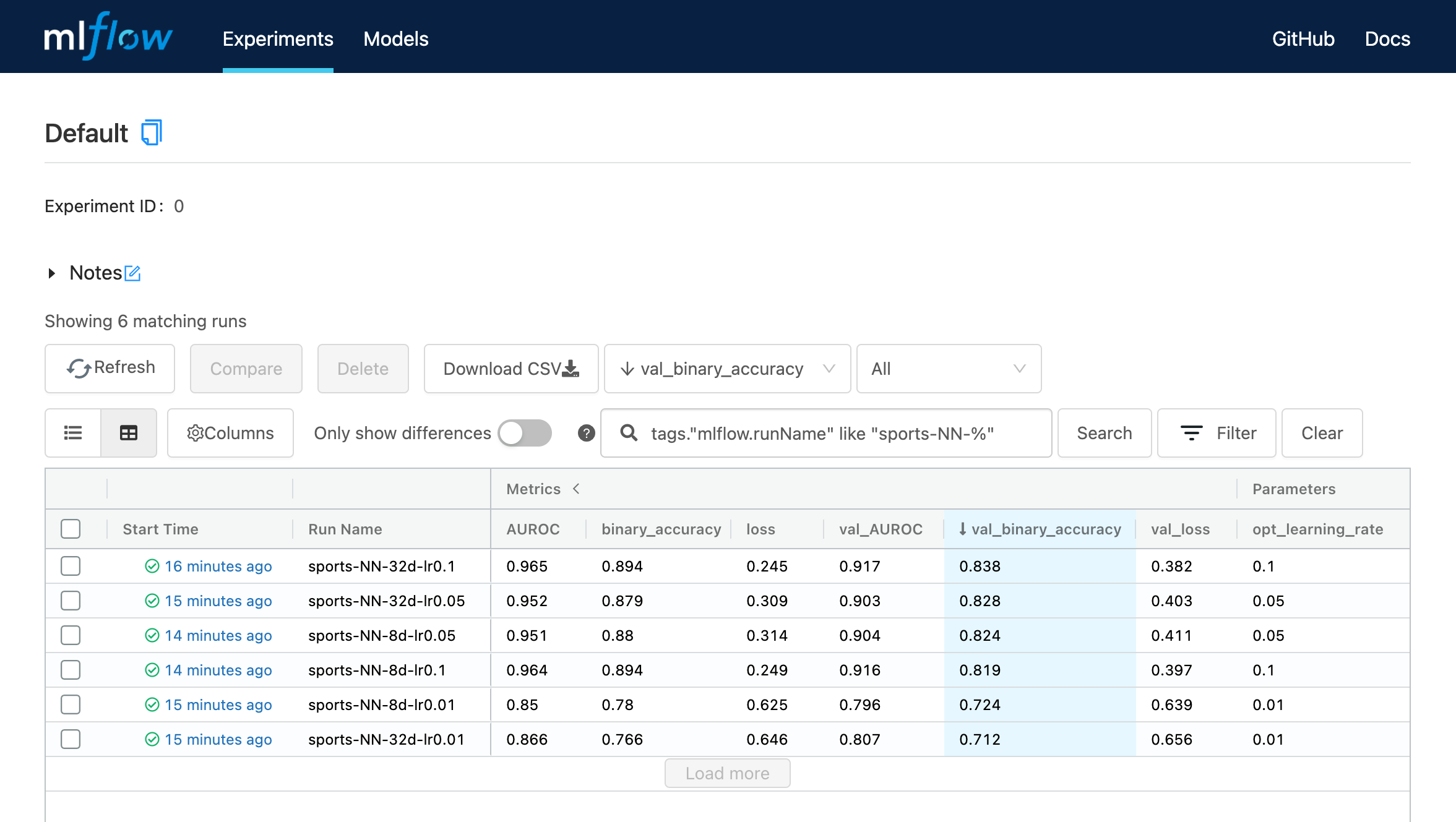
Comparing Models
As somewhat of an aside, our team really loves the built in model comparison features in MLflow. We can view many runs in a Kaggle-like Leaderboard view. For several variations of the toy example above, this looks like:
We can select several Runs and view them side by side to compare metrics and see parameters that were different helpfully highlighted. We can view plots of metrics across many runs, in a Tensorboard-like view, which helps us quickly diagnose issues like over/underfitting.
How we use MLflow for Model Review
Hopefully the above section demonstrated the awesome utility of recording and organizing all your modeling results in one place that you can easily share with others. Here I’ll explain how we’re using MLflow as a tool to implement a Model Review process as part of our ML model lifecycle.
Step 1. Training Infrastructure
We create and maintain some reasonably flexible common training infrastructure that works for most of our team’s problems.
Step 2. MLflow Tracking
We embed MLflow Tracking commands throughout this shared training code, so that experiment record keeping happens automatically (this is key) and in a standardized way. We currently track:
- all training parameters
- a unique identifier for the training data
- environment (including docker image, code version, training script or notebook)
- train and test metrics
- model (and related artifacts for deployment)
- common plots and post-training analyses
Step 3. Use Notes for Context
Not every unique detail of a model can be easily captured through logging to MLflow. Thankfully, each MLflow Run has a helpful Notes section at the top where you can write and render arbitrary markdown. We use this field to create a short narrative around every model we deploy. Additional model context that we find helpful includes a brief description of the model use case (business problem), summary of approaches tried and compared (including links to other MLflow Runs), and any callouts for modelers who return to this problem in the future.
Step 4. Model Review
Prior to the live launch of any new model, our team requires a “Model Review”. Our process is currently to:
- share the link to the MLflow Run early in a team channel
- select a primary and secondary reviewer: they are responsible for reading over the run and associated code
- schedule a 30 minute “Model Review” meeting to discuss, ask questions, and make suggestions (in addition to the reviewers, all team members are invited as optional)
- at the end the reviewers give their approval or (rarely) request changes that need to be made
Summary
Incorporating a Model Review step in our ML model lifecycle at Cash has really helped our team maintain transparency and accountability when deploying models. It is now nearly effortless to share results and approaches with each other. We can efficiently build off of each other’s work, and help new teammates become productive quickly.
We’ve found the overhead for implementing this process to be really low. Since we’ve embedded MLflow Tracking calls throughout our shared training infrastructure, all our ML experiments are tracked automatically and in a consistent way. We hold a short Model Review meeting prior to any new model deployment to share what we’ve worked on and gather feedback from our peers.
Our “process” is a WIP and evolving! If your team has a process for achieving similar goals around transparency, reproducibility, and knowledge sharing, we’d love to hear about it!
Note: The content of this blog post was presented at PyCon US 2022, and you can watch it on YouTube.