
Improving customer support intent classification with additional language model pretraining
Abstract: Labeled data are a crucial component for many NLP tasks, but are typically time consuming or otherwise costly to collect. Here, we describe how we improved sample efficiency of labeled data for a customer support intent classification task with additional language model pretraining on Cash App support cases.
Introduction
To help our customers get the support they need using Cash App, we’re building a platform which can provide them with answers to their questions quickly and accurately, day or night. For example, customers may want to know how to access an old account or perhaps they need to report a lost Cash Card. To do this, we use a combination of machine learning and people. We are constantly learning from the interactions and conversations we have had with our customers to better inform our processes. An example where a customer wants to access an account from their previous phone number is depicted below.
One way to use machine learning to automate support conversations (depicted here) is to propose solutions to customer issues (or collect additional information from the customer for the human support representative) by classifying the customer’s intent using a transformer-based model like BERT [1] followed by selecting candidate solutions from rules that are constructed from the intent and other metadata from backend systems (for example, whether the customer has ordered a Cash Card).
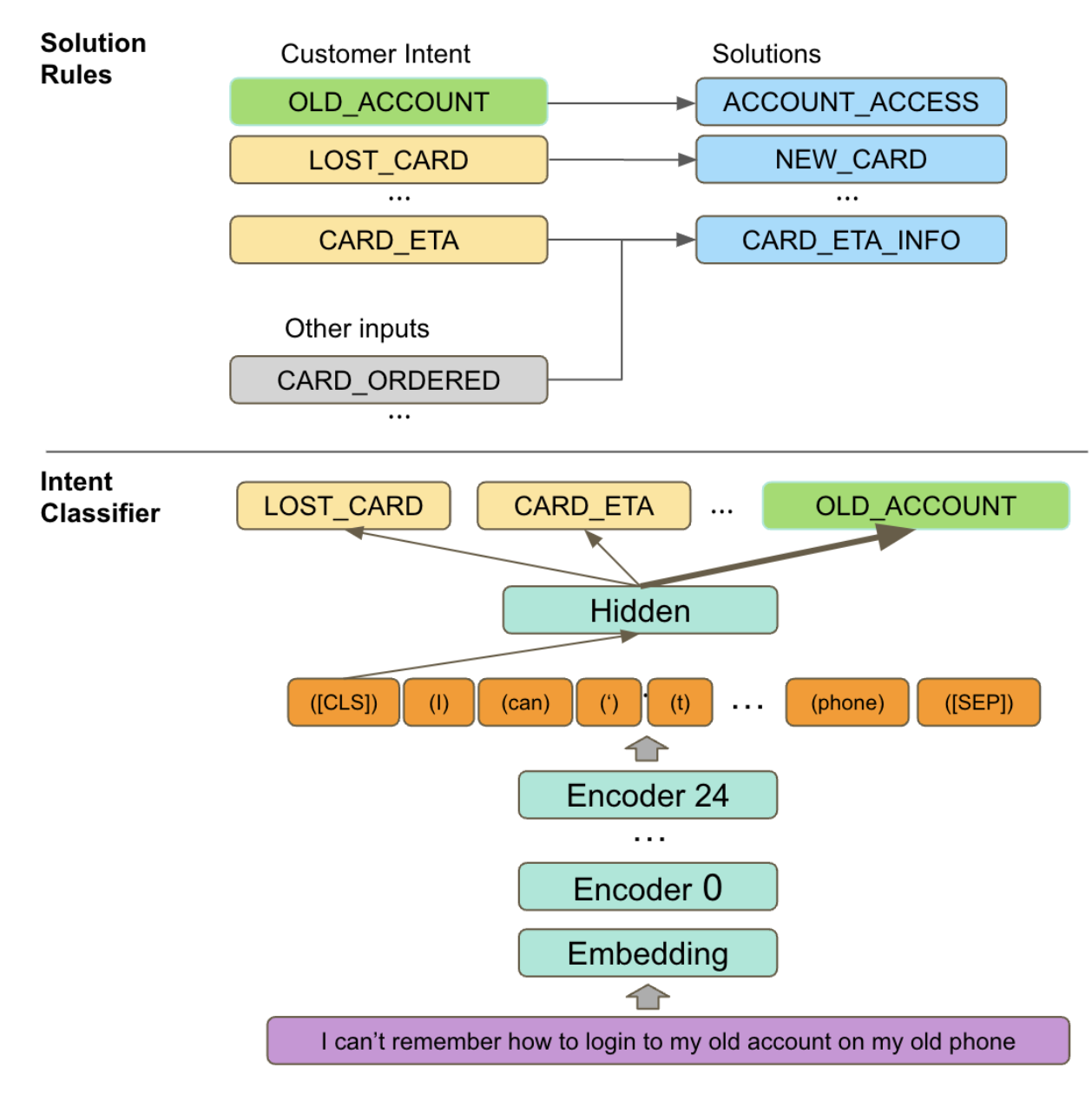
The intent classifier uses hand labeled examples that map customer support requests to our intent ontology because they are higher quality than labels that can be automatically extracted from customer support cases. However, hand labeling is a time consuming process, so we are interested in improving sample efficiency as a means to faster iteration on our intent classification models. This is possible with additional language model pretraining.
In the following sections, we describe our approach to pretraining a language model on customer support cases and experiments that characterize its improved sample efficiency on a typical customer support intent classification task.
In-domain pretraining
Modern NLP adopts a two-staged training approach of pretraining followed by fine-tuning. In the pretraining stage, we start with a large unlabeled dataset (typically GBs of raw text) and a randomly initialized model. We then perform pretraining using one or multiple self-supervised tasks such as Masked Language Modeling (MLM) and Next Sentence Prediction (NSP), popularized by BERT’s pretraining [1]. After pretraining, we fine-tune the model end-to-end on a downstream task of interest with a labeled dataset.
Instead of directly fine-tuning an off-the-shelf model, we can continue pretraining the model on additional data from our domain before fine-tuning. This can be useful if there is not much overlap with the original pretraining dataset and especially so when labeled data for fine-tuning is limited but unlabeled data for pretraining is abundant [2].
For our additional in-domain pretraining, we extracted about 28 million customer support conversation snippets from the initial customer inquiry up until a human support representative’s first response. The dataset weighed in at 3.1 GB and comprised 650 million word tokens.
We pretrained using BERT’s Masked Language Modeling task but omitted the Next Sentence Prediction task as many customer inquiries are only a single sentence and more recent work on pretraining has questioned its effectiveness [3]. We used the whole word masking variant which has been shown to produce better results on downstream fine-tuning tasks. For example, given our example utterance “I can’t remember how to login to my old account on my old phone”, we might mask some words to create the training example:
Input:
“I can’t remember how to login to
my old [MASK] on my (RAND) phone”
Label:
[account, old]
BERT’s Masked Language Modeling randomly masks 15% of tokens or words in each input sequence up to a maximum of 20 masks. 80% of the time masking uses the [MASK] token, 10% a random token, and the remaining 10% of the time is left unchanged. We masked each customer inquiry and wrote out TFRecord files for the pretraining task that included the masked token sequences as well as the masked indices and correct tokens padded up to the maximum of 20 masks. We chose TFRecords because they are an efficient binary storage format for our preprocessed data that can be sharded to parallelize I/O during training and benefit from prefetching when large enough.
Given the masked token sequences, the Masked Language Modeling task is to predict the original unmasked tokens, thus minimizing the cross-entropy between each one-hot encoded label and predicted probability distribution over tokens, ignoring the cases where there were fewer than the maximum number of masks.
We continued pretraining from the BERT-large whole word masking checkpoint using the Adam optimizer with a learning rate of 1e-5 for 100K steps with a batch size of 512 which was sufficient for convergence on our dataset. We used a sequence length of 128 tokens which was possible due to the relatively short nature of our customer inquiries.
On 8x 40GB NVIDIA A100 GPUs, pretraining takes a little over 24 hours. Due to the data size, we felt the concept of an “epoch” – a full pass through the dataset – broke down and instead logged metrics and checkpoints every 5000 steps to assess convergence.
Downstream intent classification task
We compared the effect of in-domain pretraining to “vanilla” pretraining (the off-the-shelf checkpoint we started our pretraining from that is typically used for downstream classification tasks) when fine-tuning on an internal 14-way support intent classification task. In general, we find in-domain pretraining helps fine-tuning to converge in fewer epochs and lifts metrics such as precision and recall by up to 10% depending on the number of training samples.
To assess sample efficiency, we measured peak recall over epochs at a fixed precision of 80% as (Recall@80) a function of the number of training examples per class.
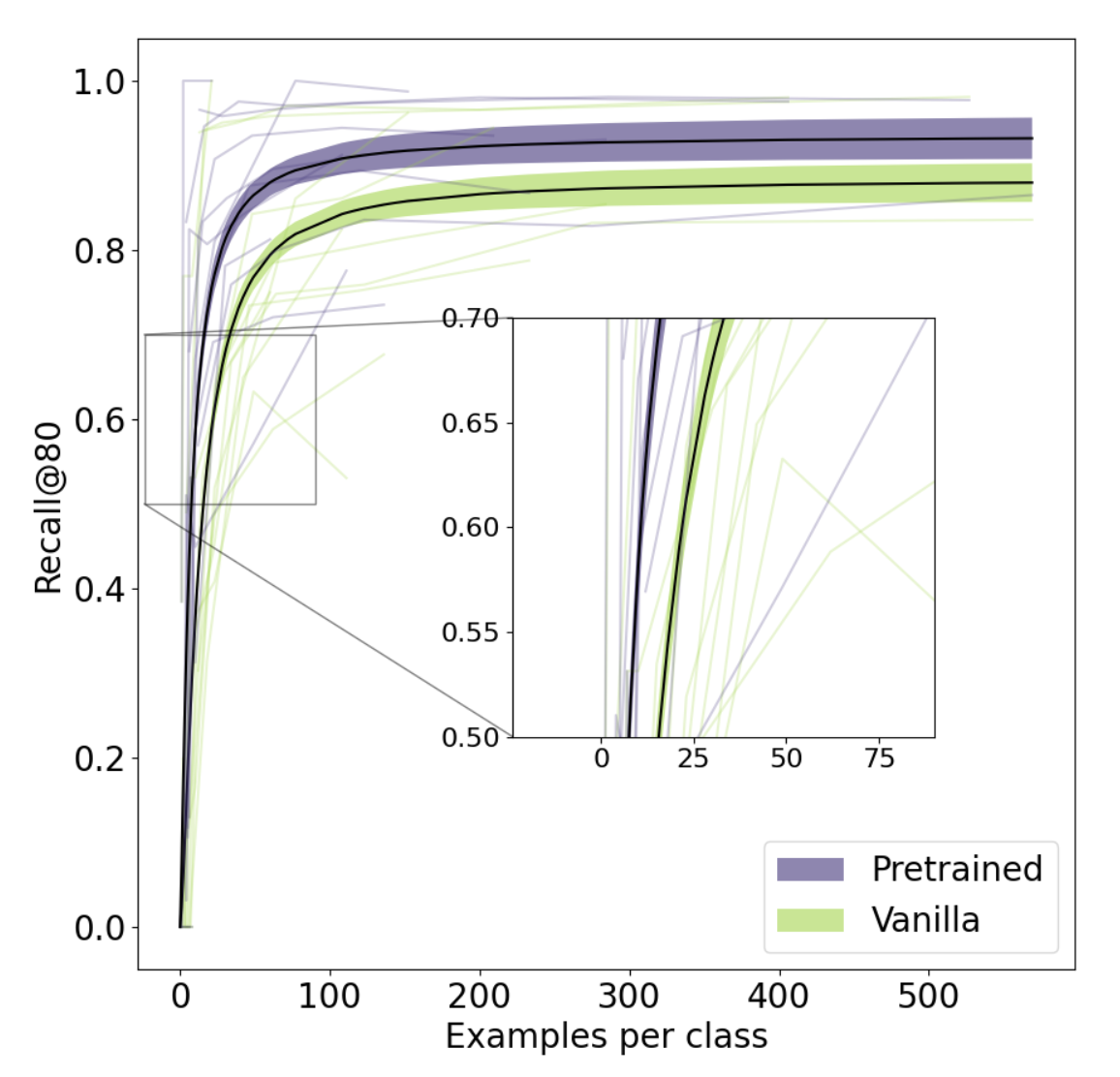
Looking at these learning curves, we see that differences in recall are most pronounced when there are few examples per class (e.g., fewer than 50).
We also fit an aggregate curve to these data and recorded the number of samples required to reach a given level of recall on average.
| Recall@80 level | Pretrained BERT | Vanilla BERT |
|---|---|---|
| 50% Recall | 10 | 18 |
| 60% Recall | 12 | 28 |
| 70% Recall | 18 | 39 |
| 80% Recall | 34 | 77 |
| 85% Recall | 60 | 275 |
| 90% Recall | 200 | NA (not reached) |
We find a roughly 2x increase in sample efficiency for a given Recall@80 which means that to achieve a similar level of performance, our pretrained BERT requires half as many samples as vanilla BERT. Our pretrained BERT can also reach higher recall than the vanilla BERT while maintaining 80% precision.
Summary
We’ve found in-domain pretraining useful since it helps us classify new intents from our customer support ontology with about half as much data as vanilla pretraining, leading to faster iteration on our models. This sample efficiency happens through knowledge extracted from the large amounts of unlabeled data we automatically receive through customer support cases so that we require fewer, more difficult to acquire hand labels.
Since our initial implementation, pretraining tasks have gained support in third party libraries such as Hugging Face transformers. These implementations make it relatively easy to perform dynamic Masked Language Modeling (in which masks are generated on-the-fly instead of statically per example) which may improve pretraining [3].
In the future, we want to continue exploring ways to incorporate more of the support case conversation into our pretraining (e.g., including responses from human support representatives) and investigate implementing additional tasks that are more specific to conversations such as dialog modeling [4, 5].
Acknowledgements
This work was done collaboratively by Victor Li and Dean Wyatte. We would like to thank Isaac Tamblyn and Ryan Brackney for providing helpful suggestions for this article.
References
- Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
- Gururangan, S., Marasović, A., Swayamdipta, S., Lo, K., Beltagy, I., Downey, D., & Smith, N. A. (2020). Don’t stop pretraining: adapt language models to domains and tasks. arXiv preprint arXiv:2004.10964.
- Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., … & Stoyanov, V. (2019). Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692.
- Wu, C. S., Hoi, S., Socher, R., & Xiong, C. (2020). TOD-BERT: Pre-trained natural language understanding for task-oriented dialogue. arXiv preprint arXiv:2004.06871.
- Wang, P., Fang, J., & Reinspach, J. (2021, November). CS-BERT: a pretrained model for customer service dialogues. In Proceedings of the 3rd Workshop on Natural Language Processing for Conversational AI (pp. 130-142).