
Blizzard: A Lightweight, Yet Powerful ML Feature System for Prototyping and v1 Use Cases
Introduction
This post is about Blizzard, a machine learning feature system we’ve built at Block’s Cash App for prototyping and early v1 production ML use cases. Blizzard demonstrates how a tremendous amount of value can be obtained by pairing a Python library with a data warehouse. While we already have a robust production-oriented feature system at Cash, that system has had to make tradeoffs to support scale and real-time evaluation that Blizzard hasn’t. Consequently, we use both systems, each serving a different niche within Cash’s ML ecosystem. This post highlights the features and design of Blizzard and situates it within the set of ML feature system choices companies typically have to make.
For those unfamiliar with the topic, a feature system is, broadly-speaking, used to define, compute, store, and serve values that can be used as input to ML models. Feature systems will perform some or all of these activities depending on the goals of the system. Feature systems typically deal with so-called structured features which include counts, sums, and averages aggregated over events and transactions as well as scalar attributes such as an account’s age, the day of week, or a merchant’s category. Feature systems help to standardize, automate, and enhance what is (arguably) the most important part of the traditional ML process.
System Overview
The Blizzard system architecture leverages an in-house Python library paired with our already-existing Snowflake data warehouse. The warehouse provides both the underlying data and the feature computation and storage capabilities. The library houses a repository of abstract feature definitions which is used to generate the concrete executable feature creation code. The library also orchestrates feature creation using the warehouse’s compute and storage capabilities.
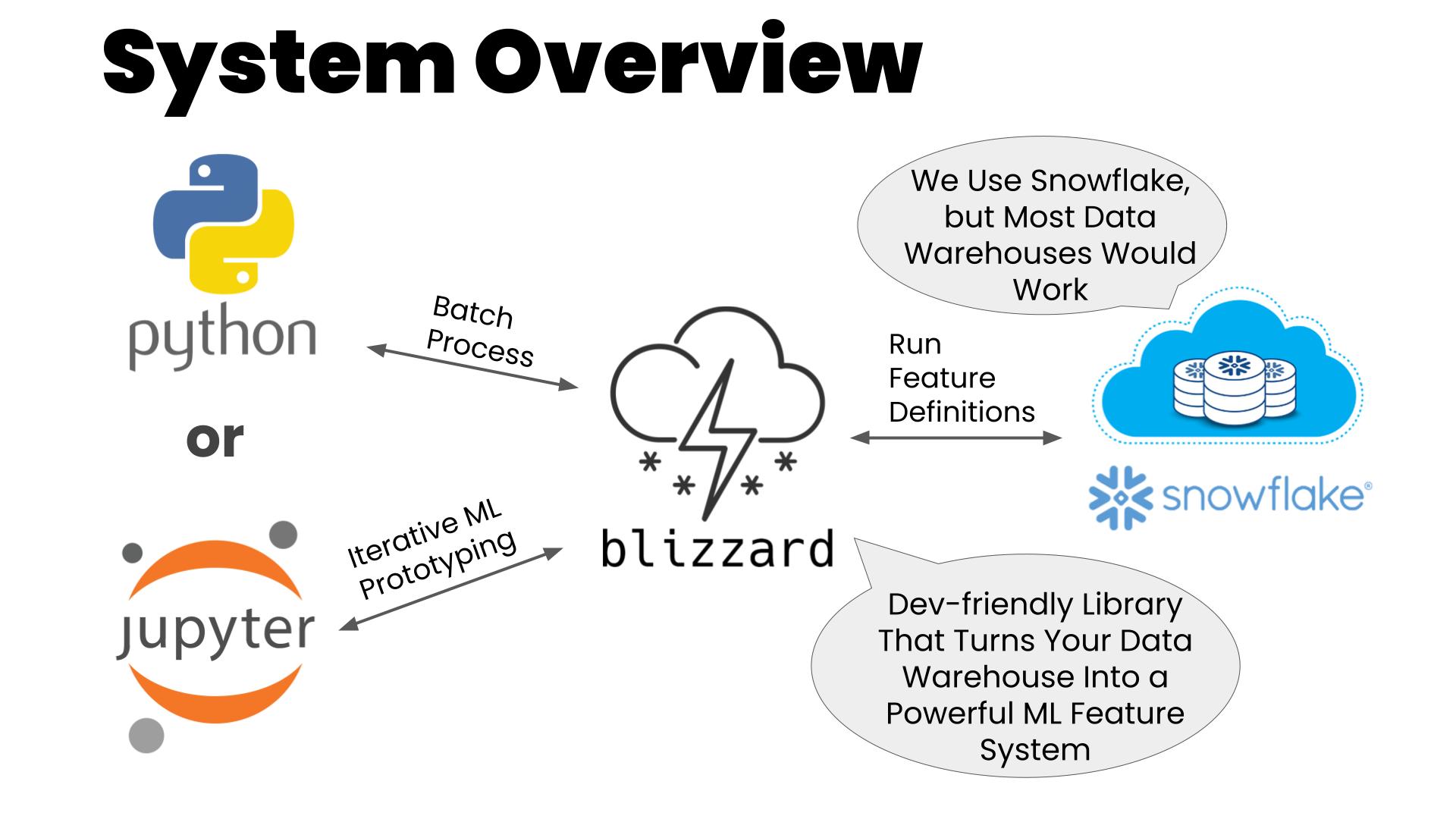
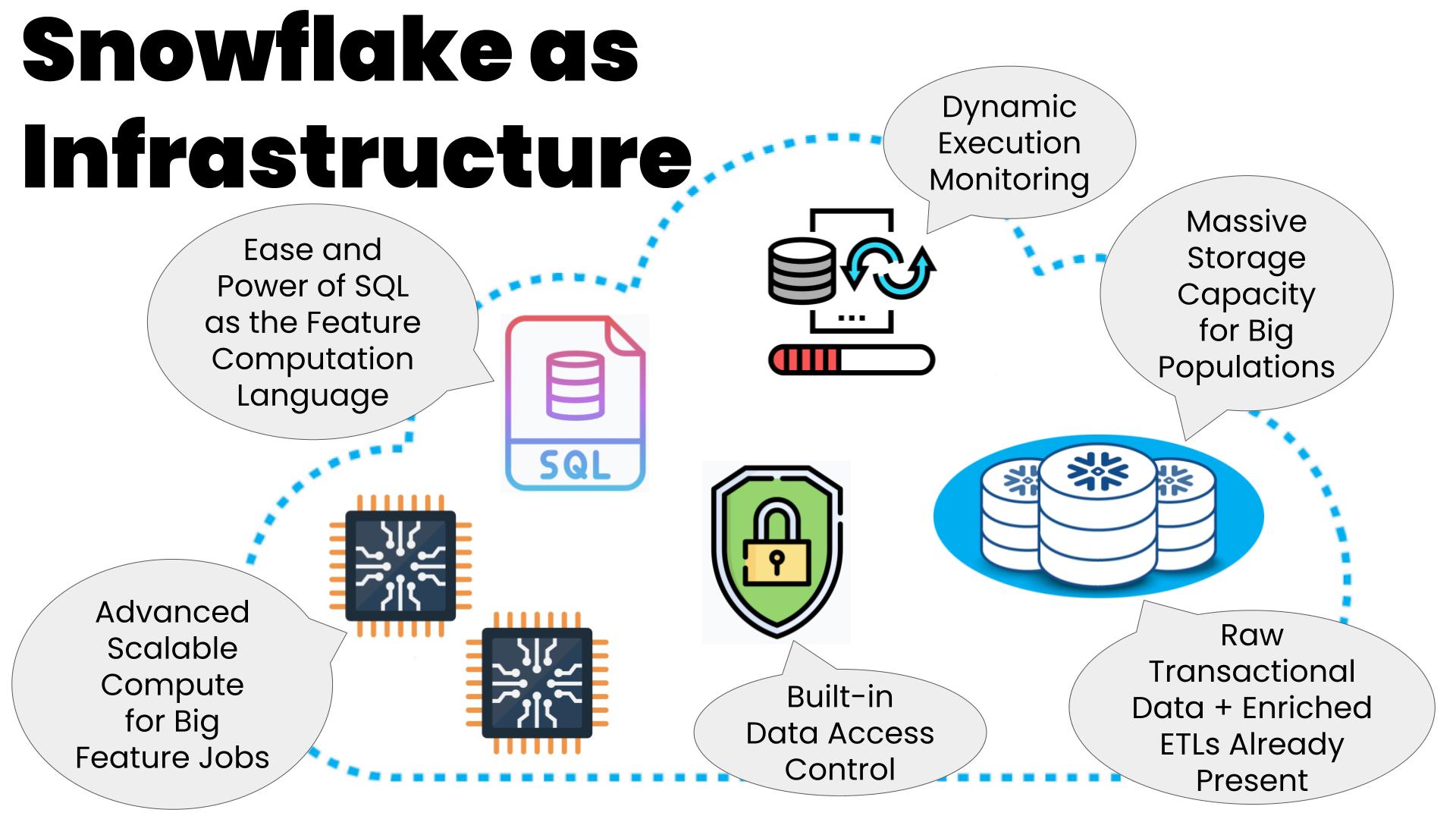
Why Use a Data Warehouse?
Most production-oriented feature systems have robust, higher-scale compute and storage subsystems. This is true of home-grown systems like Cash’s and of vendored solutions like Tecton, Feast, or AWS SageMaker Feature Store. But the costs to buy, build, operate, and/or maintain these systems can be large and the set of tradeoffs for which these systems are optimized often leaves a number of valuable needs unmet. Blizzard’s choice of a standard data warehouse like Snowflake for its backend provides a number of advantages for getting up and running quickly with a lower-cost lightweight feature system:
- Like Cash, most every consumer-oriented company already has a data warehouse for analytics and research. The company’s product transactional data is typically all available here, as well as many layers of enriched ETL data on top of that. This data richness provides excellent raw material for an ML feature system.
- As long as you don’t have real-time requirements on your feature computations, then a data warehouse is more than adequate for a large range of feature computation workloads.
- Storage of the computed features is well supported since data storage is one of the primary functions of a warehouse.
- If your warehouse has a simple SQL execution API like Snowflake, then automating the creation of executable feature queries is both easy and powerful compared to something that is very powerful, but not as easy, like a Databricks Spark-Python-oriented warehouse.
- For access control, it’s straightforward to reuse the permissioning capabilities already built into the warehouse.
- Snowflake, like most warehouses, has an API for monitoring job progress and statistics which can be exposed to users for observability and debugging purposes.
Feature Definitions
Flexibility and modularity in defining features are two of the primary axes that feature systems vary on. Systems that define features in a config language like YAML, while simple, can be only moderately flexible and modular. Blizzard, which defines its features as Python classes and functions, allows for highly flexible and modular definitions with only a little added complexity beyond static approaches like YAML.
The Blizzard feature definition system depends most heavily on the following types:
- Entity
- EntityType
- DataSet
- FeatureDefinitionGroup
- Features
Entity and EntityType
An EntityType is a conceptual type for which we want to create and aggregate features for, such as a customer, a merchant, a device, a postal code, etc. An Entity is a concrete instance of a certain EntityType, e.g., a customer_token Entity of EntityType “Cash Customer” or a merchant_token Entity of EntityType “Cash Card Merchant”.
DataSet
A DataSet is a SQL query and a Python config class corresponding to events involving one or more Entity tokens, e.g., a Person-to-person Payments DataSet having sender_token and recipient_token Entity columns (both of EntityType “Cash Customer”) and data columns like created_at, paid_out_at, and amount_cents.
FeatureDefinitionGroup
A FeatureDefinitionGroup is group of related feature definitions based on the data in its associated DataSet, e.g., a Person-to-person Payments FeatureDefinitionGroup group would contain the Python code to generate features akin to SQL expressions like count(distinct customer_token) and sum(amount_cents).
Features
At the lowest level, Features themselves are created by making calls within a FeatureDefinitionGroup to various helper functions. These helpers can create aggregated, ratio, and non-aggregated features. Blizzard also has a suite of convenience helpers that generate sets of features by iterating over one or more related input collections, such as aggregators (e.g., sum(), count(), avg()) and time windows (e.g., last week, last month, between 6 and 12 months ago). When these helpers aren’t enough, custom Features can be created (with care!) using any arbitrary SQL compatible with the underlying Entities being grouped.
Basic feature development involves creating new Features within an existing FeatureDefinitionGroup using helper functions. Intermediate and advanced feature development involves creating new EntityType, DataSet, and FeatureDefinitionGroup classes.

Feature Developer Experience
Blizzard optimizes for the feature developer experience in a variety of ways:
- Definition files are plugged in by checking them into a centralized definitions folder in the Blizzard repo.
- Adding a new DataSet only requires checking in a simple configuration class and a sql query.
- Adding a new grouping EntityType only requires checking in a simple configuration class to the definitions folder.
- Adding Feature definitions only requires adding new helper function calls to an existing FeatureDefinitionGroup.
- Feature definitions within FeatureDefinitionGroups are highly customizable Python code.
Feature End User Experience
Blizzard optimizes for the feature end user experience by providing a feature retrieval API that is easy to get started with using default parameters and yet is powerfully customizable in its parameter overridability.
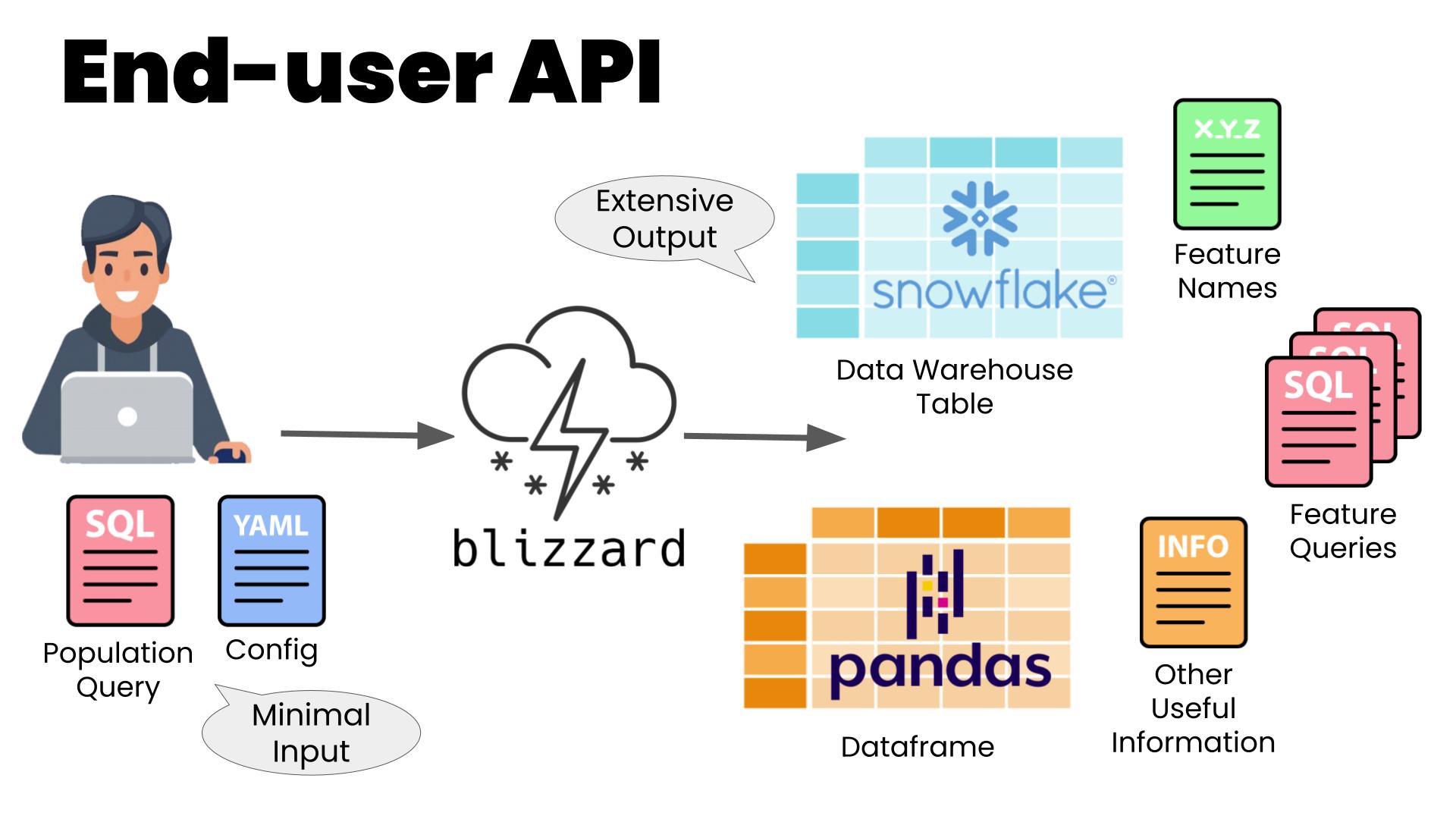

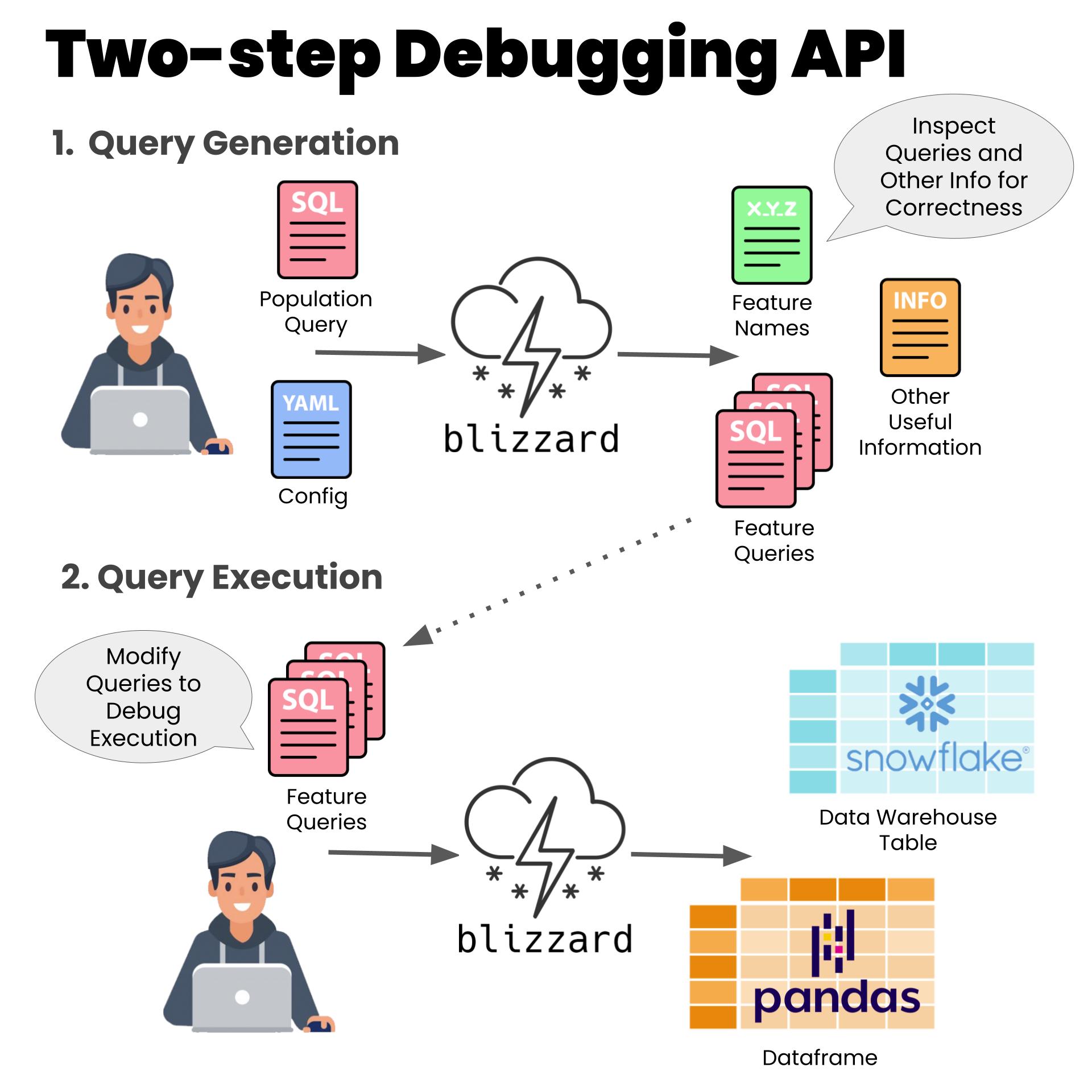
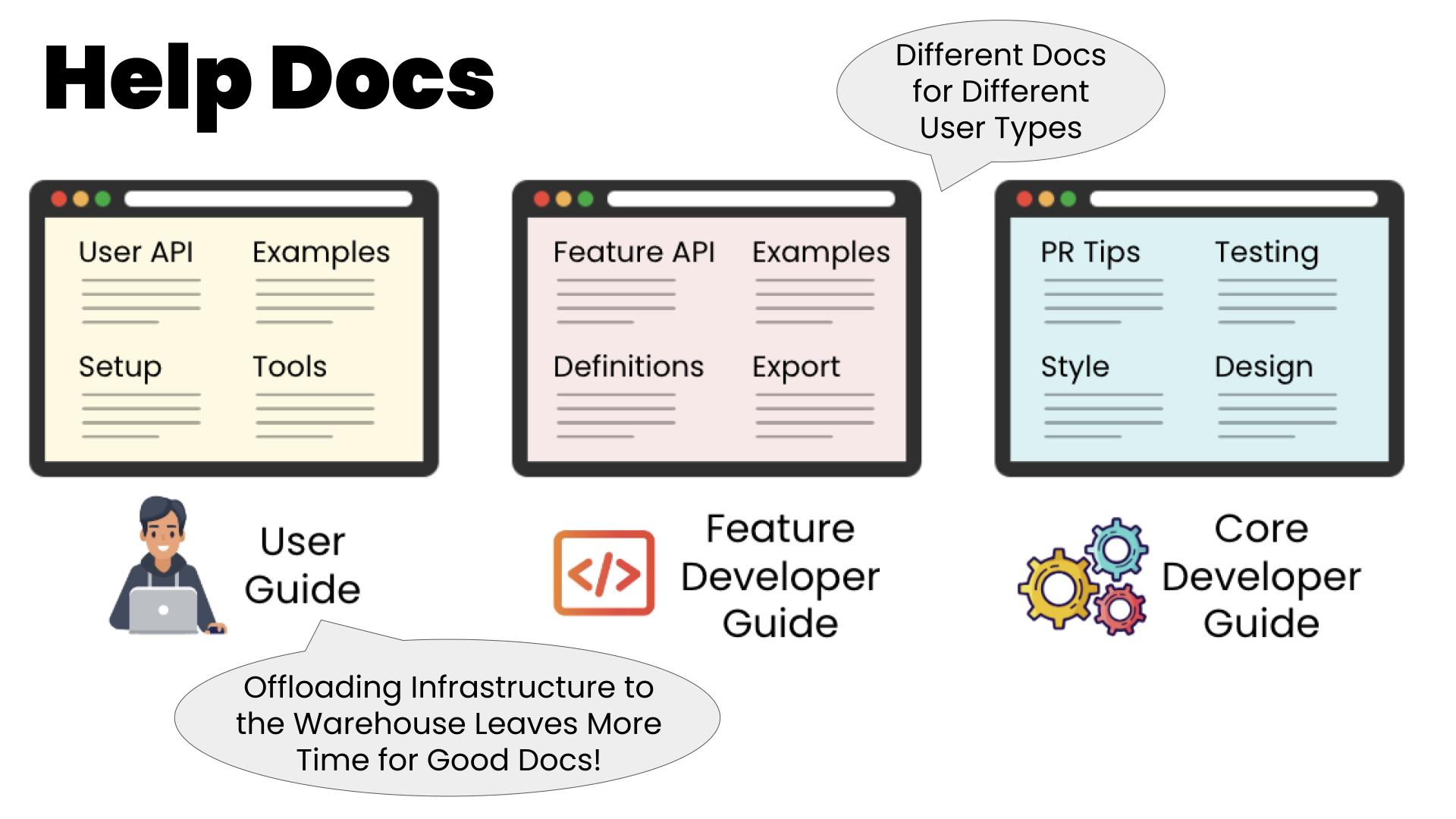
Documentation
Feature systems have two primary user types: end users who want to use features for their ML models and feature developers who want to define useful features for end users. Most feature system documentation, however, focuses only on different functional actions any given user can take, leaving the different user types and their distinct user experience profiles implicit. By making user types explicit in the documentation, you can better tailor to the user type the style of language used, the examples, and the types of information covered. In the case of an end user versus a feature developer, these differences can be quite prominent, and so organizing by user type can be quite beneficial for user effectiveness and satisfaction.
In the case of an in-house system like Blizzard, or if a system like Blizzard was open-sourced, there is also a third user type: a core developer who wants to maintain and extend the functionality of the feature system itself. Adding documentation for this third user type in the typical lower-level, functional-orientation we see with many feature systems’ documentations would add additional clutter for the two primary user types already mentioned.
To embody this user-type-centered philosophy, Blizzard’s documentation reflects its three different user types explicitly. It contains an end user section with setup instructions, numerous working examples, API references, utilities, and tools specifically geared toward the end user experience. It contains a feature developer section with a feature definition browser, simple and advanced definition examples, API references, and tools specifically geared toward the feature developer. Finally, it contains a core developer section centered around development environment setup, system testing, PR standards, and core developer tools.
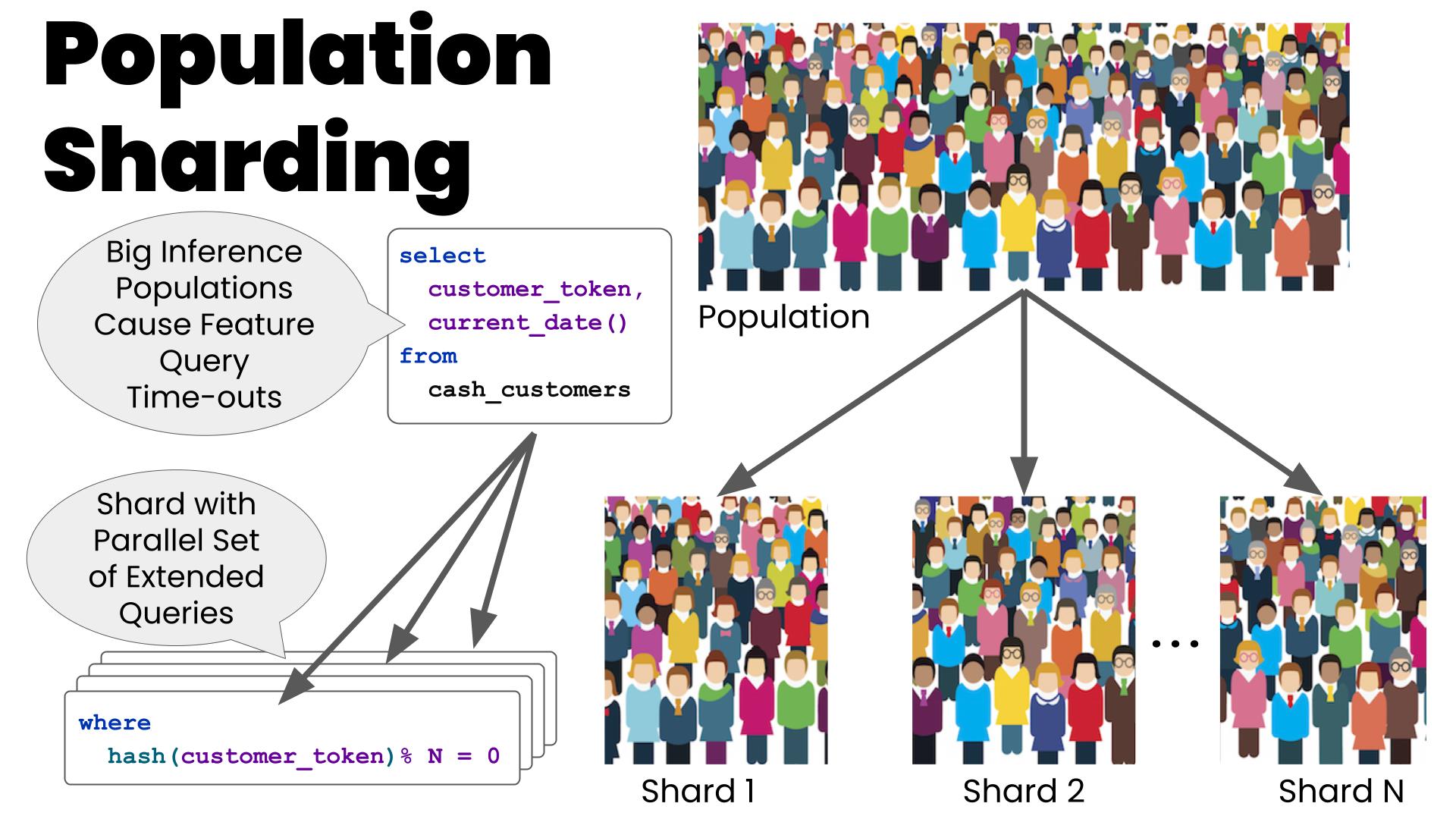
Scale Enhancement
One of the primary constraints of using a data warehouse is the practical scale limits inherent in processing SQL constructs like joins and unions on large population data sets. In our case, while Snowflake provides impressively configurable warehouses with different memory and compute capacities to match our query workloads, there are always upper limits on what can be accomplished in a timely and cost-effective manner in a single query. This is the case with other warehouse vendors as well. Blizzard mitigates this to a large degree by allowing for sharding of the input population query into a set of population queries segmented by the population’s primary Entity token.
Prototyping
Blizzard shines as a prototyping tool. Most production feature systems require data sets to be configured and ingested specially for each new data source. By using the data warehouse, you typically have all available data already accessible. In addition, it is typically very easy to create a new ETL in a data warehouse to enrich or further aggregate the basic data sets. You might want to aggregate transactions by week and then compute features on the weekly summary data rather than on the raw transactions themselves. Or you may want to aggregate individual impressions and selections of recommended content into sessions and compute features on the session-level summary data. You can create and run simple ETLs like these and plug in the required DataSet and Feature code in the Blizzard library in just a few hours to validate and iterate on your intuitions. Even faster, you can skip the ETL step while in development and iterate directly using ad hoc queries to power your Blizzard DataSets. In our experience, we can create ~10x-100x the number of features in a given amount of time in Blizzard versus our other production-oriented feature systems.
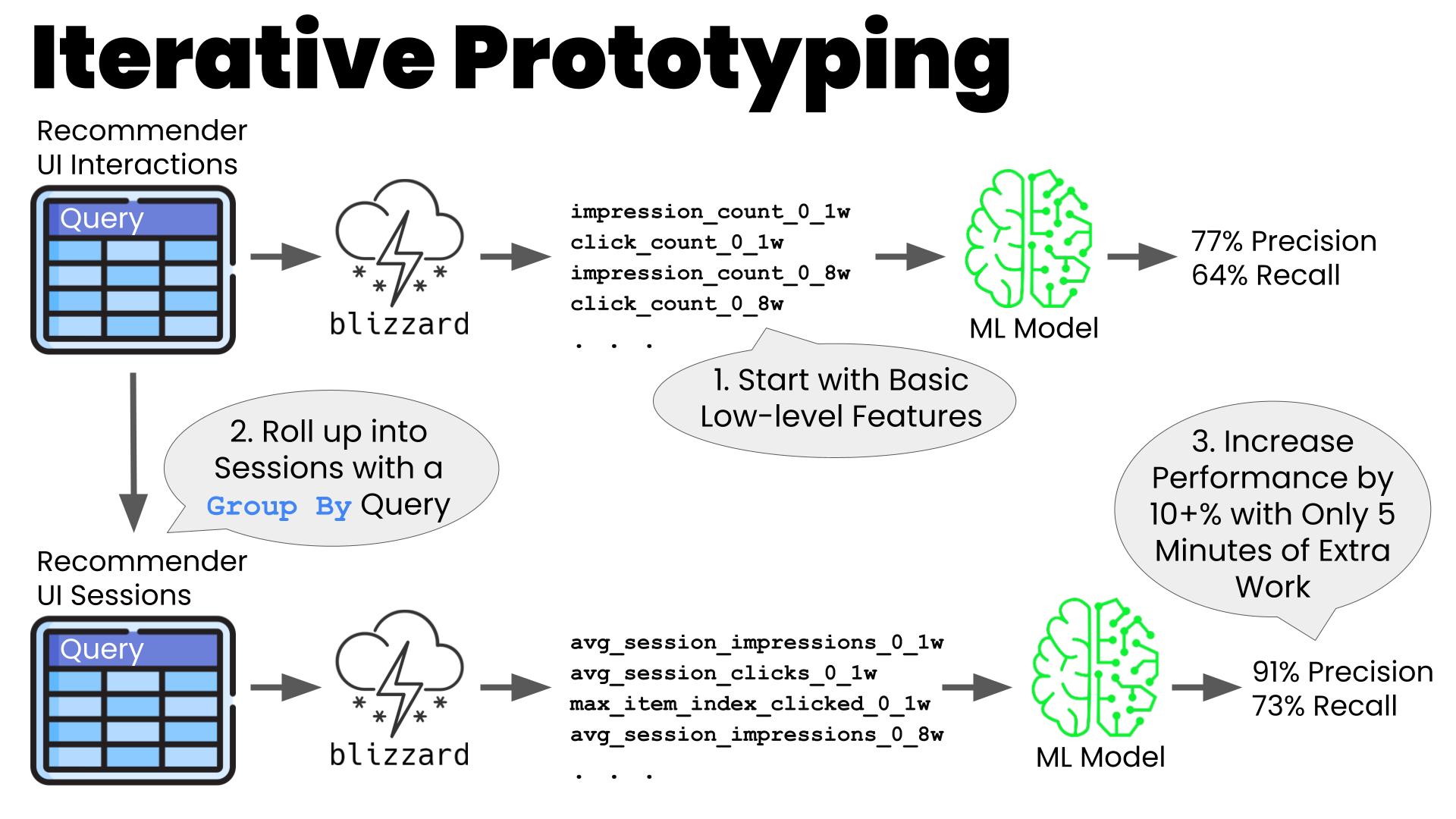
The simplicity, speed, and lack of cumbersome controls typically found on more production-oriented systems highly facilitates Analysts and Product Data Scientists who don’t use ML regularly to explore and experiment with ML in their work.
Blizzard is also great for validating that a previously-unused data source would be valuable for a real-time ML scenario. Blizzard supports timestamp-level aggregations allowing it to time travel at high resolution, a must for validating real-time scenarios with historic data.
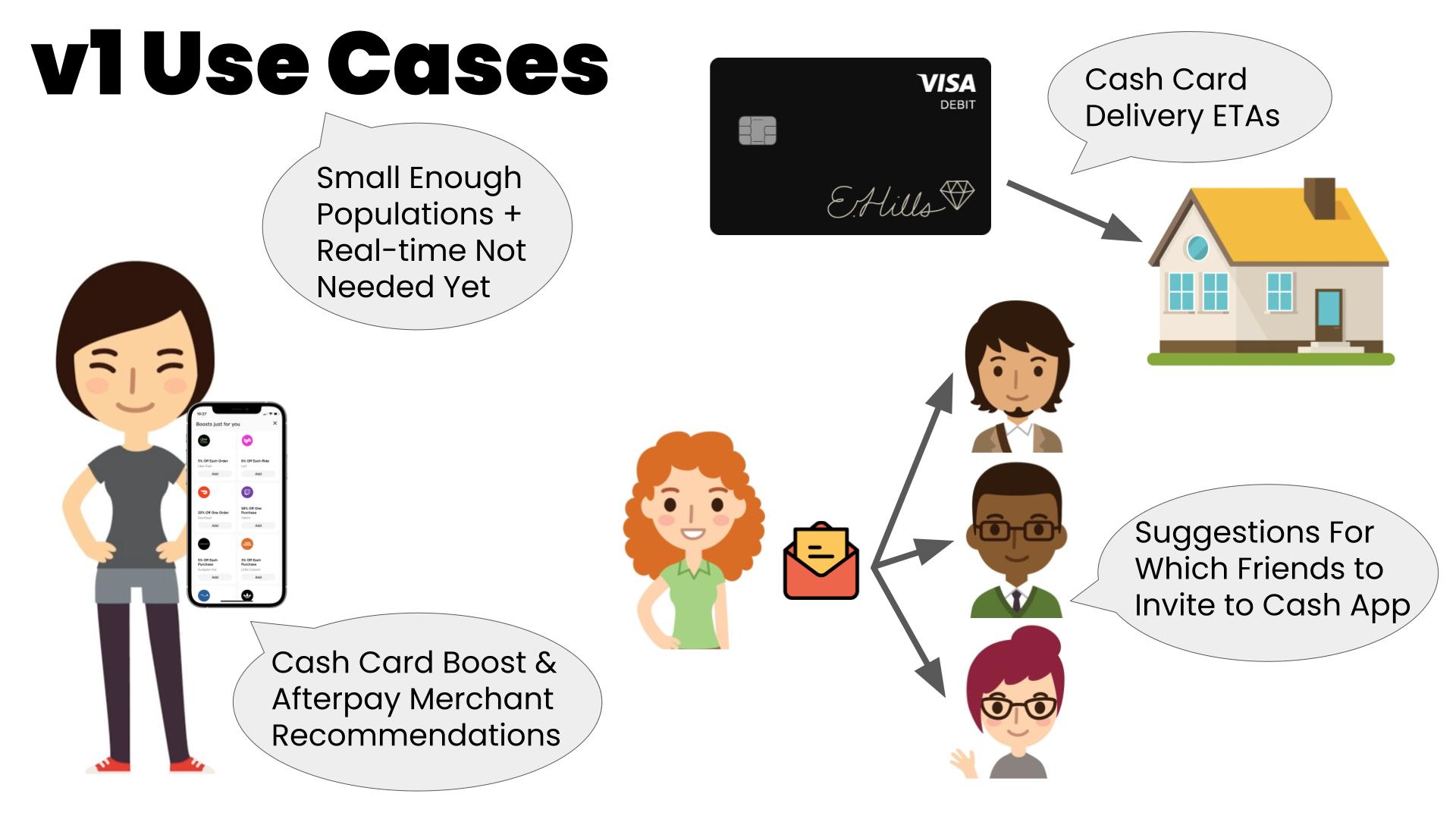
v1 Use Cases
Blizzard is great for certain production use cases too, especially v1 scenarios where the feature freshness can tolerate up to a day of lag (the typical refresh cycle of a warehouse) and the population to be batch-inferenced can be reasonably pre-filtered so as not to exceed the memory and compute capacity of the data warehouse. It turns out that a surprising number of use cases match these criteria. At Cash, for example, we’ve used Blizzard to power v1 ML models that recommend Boost rewards and Buy Now Pay Later Merchants to customers, that calculate shipping times of a customer’s newly ordered Cash Card, that recommend contacts for customers to refer to Cash App, and many others.
Limitations
Of course, Blizzard’s many advantages come with some limitations. In addition to the already mentioned warehouse-related limitations of non-real-time feature evaluation and inability to process massive scale populations, there are several other notable ones to keep in mind for systems like Blizzard:
-
Typical warehouse data governance at most companies is loose, dynamic, and uncentralized. While this leads to high velocity and agility for data analytics and evolving research purposes, this can lead to tables and columns having their underlying structure changed in a direct breaking fashion or have their distributions change more subtly without downstream systems like Blizzard knowing about it immediately. This can cause instability across time in one’s ML modeling.
-
Companies generally choose to store their warehouses data in the customary relational table format, e.g., one row per transaction in a transactions table. Since data isn’t stored as immutable transaction logs like in many production-oriented feature systems, any mutable column, e.g., a transaction status column that changes over the life of the transaction, won’t be usable in Blizzard because it would introduce so-called time leakage into features based on it.
-
Blizzard requires one to be a moderately skilled Python developer to effectively add features to it, blocking Python novices from using it to its fullest extent.
Final Thoughts
Whether it’s being used to quickly research new ML use cases or accelerating early v1 productionizations, Blizzard fills a valuable niche in the feature system landscape. It achieves its lightweight, yet relatively powerful profile via a deliberate set of tradeoffs around non-massive scale, non-real-time evaluation, and looser data governance.
Future work includes integrating Blizzard with additional data warehouses beyond Snowflake, exporting Blizzard definitions to work within Tecton to provide us with a hybrid higher-scale feature system, and investigating the feasibility and demand for us to open source Blizzard.
If you’re interested to discuss Blizzard further or have any feedback on this post, hit me up at cskeels@squareup.com or Christopher Skeels on Linkedin.