Turning Large Language Models into Classifiers with Predictable Scaling
Modern Large Language Models (LLMs) represent a paradigm shift in automation potential for business operations like customer support. However, they inevitably suffer from hallucination [1] making them a challenge to incorporate into applications without careful consideration of the appropriate guard rails.
In this post, we provide an overview of our recent work that safely deploys an LLM for an online customer support application by reframing single-token language generation as a discriminative process. Doing so allows us to leverage the unique scaling properties of LLMs [2] for tasks that require discrete decisions such as classification and recommendation that are commonplace in business settings.
The contributions of our work are as follows:
- We describe a pipeline that trains an LLM using a standard language modeling objective and then fine-tunes it as a classifier on labeled data.
- We examine the effect of model parameter count and training tokens on a classification task finding the relationship follows a typical scaling law.
- We discuss the deployment considerations of our approach in an online customer support application and the learnings over the period it has been in operation.
Turning LLMs into Classifiers
We build on the approach described in Label Supervised LLaMA Finetuning [3] which fine-tunes a LLaMa-based LLM [4, 5] by instantiating a classifier on top of the final transformer block and pooling embeddings over a token of interest to compute the class probability distribution. A typical LLM can be understood as performing k-way classification on the rightmost input token where the possible output tokens represent the available classes. Under this framing, the decoding loop can be understood as greedy classification with sequential input modification. This intuition provides us a clear path to turning an LLM into an explicit classifier by replacing the final output layer containing |V| logits with a layer that has |C| logits, where |V| is the cardinality of the output vocabulary and |C| is the number of classes.
While fine-tuning requires gradient updates compared to in-context learning, some classification problems may contain hundreds or thousands of classes making them difficult to fit in-context and control via prompting. Furthermore, we find turning LLMs into classifiers to be an attractive alternative to fine-tuning BERT [6] and similar models due to the popularization of longer input context in modern LLMs (e.g., LLaMA’s 8192 tokens compared to BERT’s 512 tokens, although see also [7]) and the ability to leverage more powerful pre-trained models produced by the field.
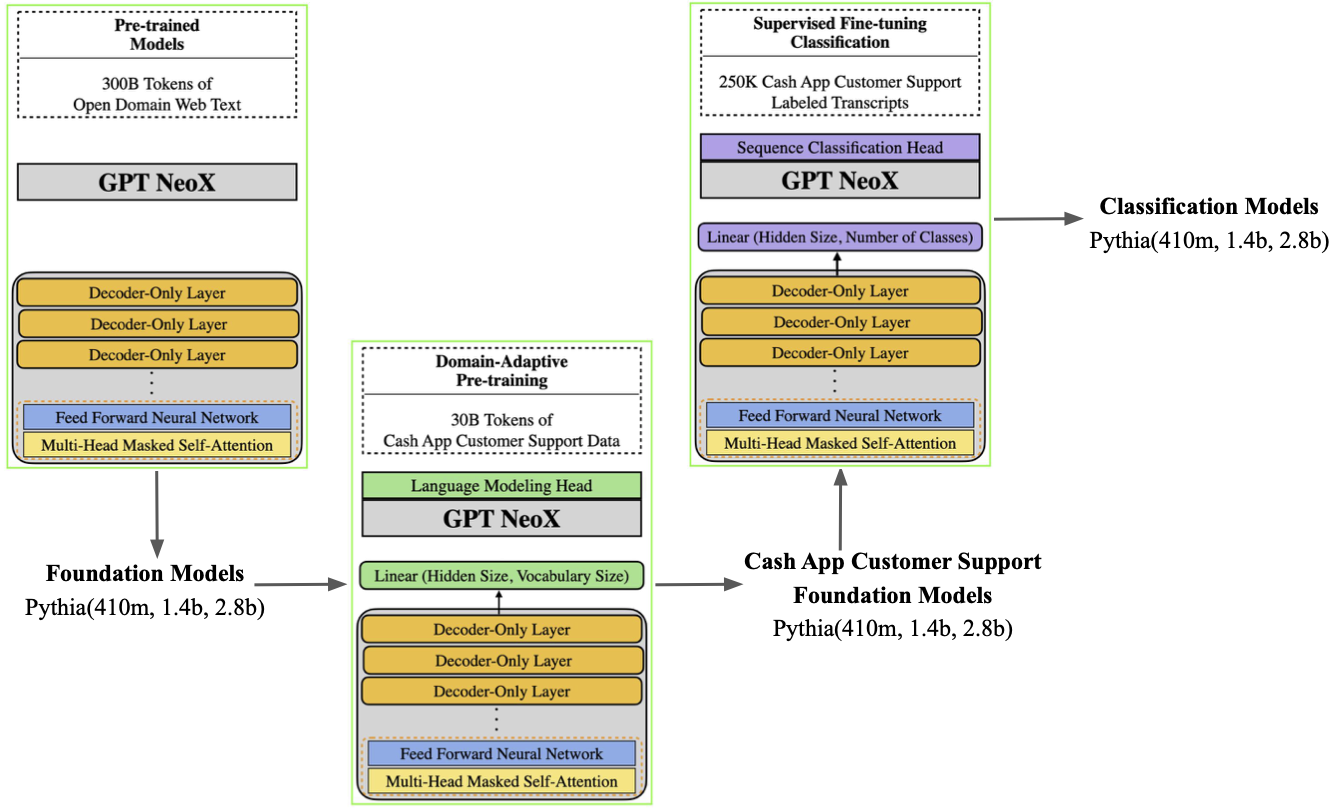
Our training pipeline is depicted below. We use the Pythia family of LLMs [8] due to their broad range of parameter counts that on the low end enable direct comparison with our previous BERT-based system [9]. We start with a Pythia LLM (410M, 1.4B, or 2.8B parameters) trained on 300B tokens of domain general web text and continue pre-training on up to 30B tokens of customer support transcripts to adapt the LLM to our specific domain.1 Finally, we fine-tune the LLM into a classifier on a smaller set of customer support transcripts labeled for a 640-way classification task.
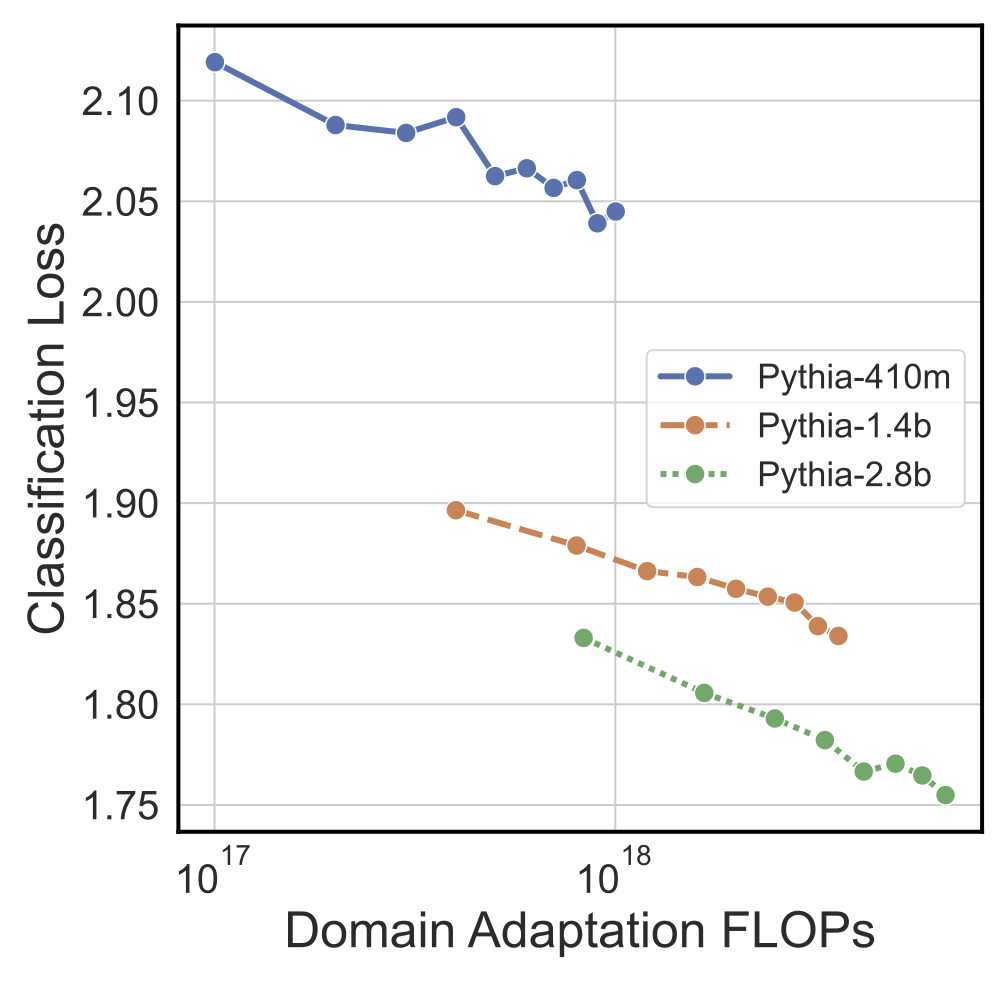
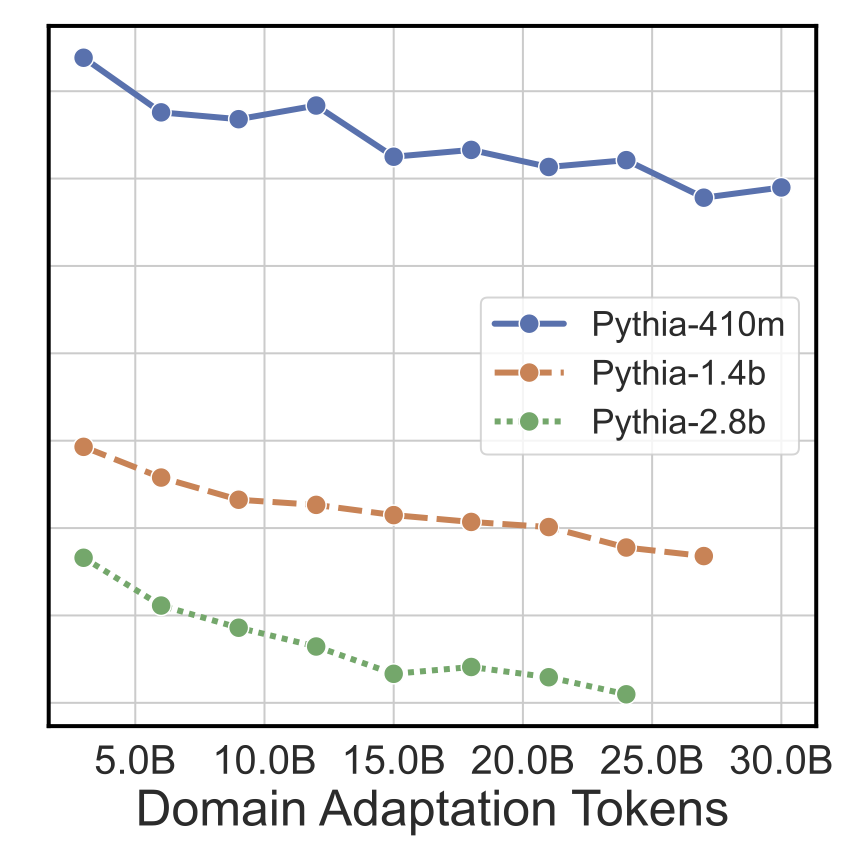
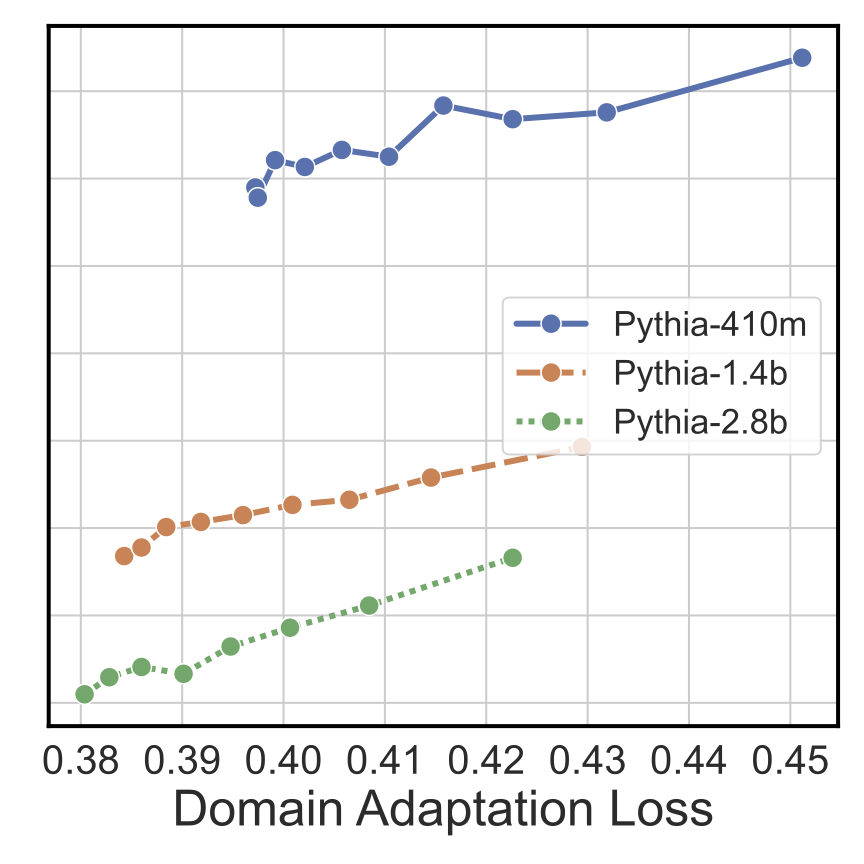
Scaling Laws of Classifiers
To understand the scaling properties of LLMs turned into classifiers, we periodically measure fine-tuning performance during our pre-training/domain adaptation step. We observe a clear linear relationship between the classification fine-tuning loss and domain adaptation FLOPs (Floating Point Operations), token count, and loss. This relationship holds for multiple model sizes with larger LLMs performing better. Together, these results indicate we are reliably able to produce better classifiers by scaling the data and model during pre-training/domain adaptation.
 |
 |
 |
|---|
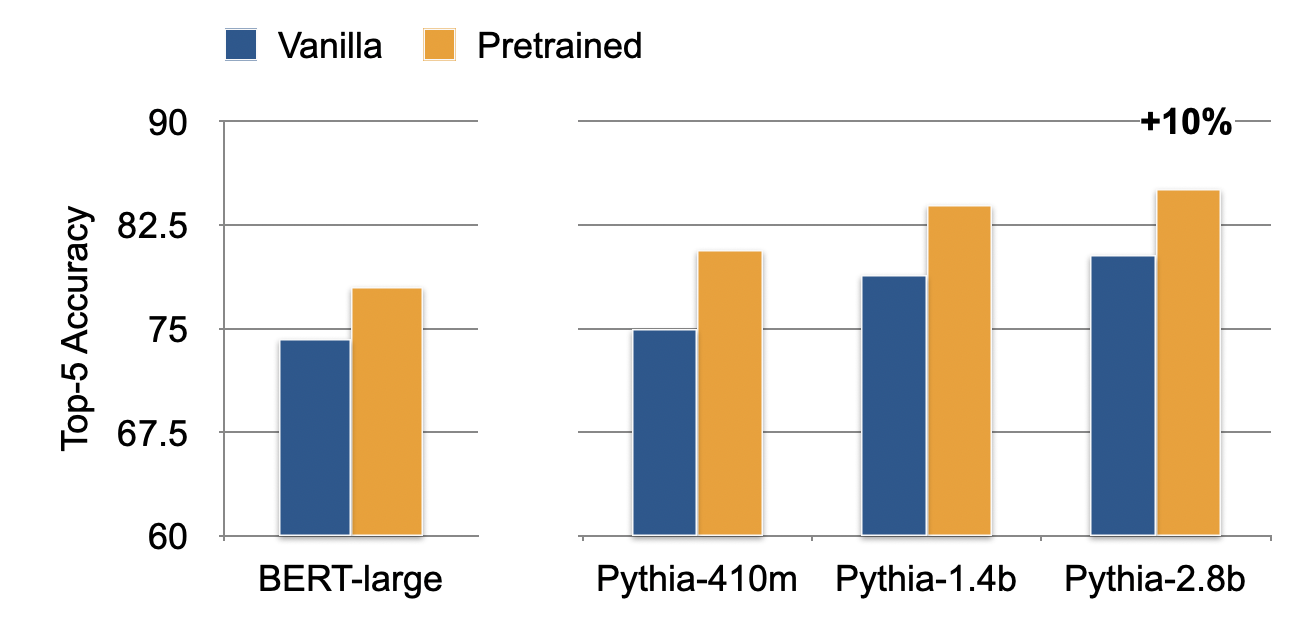
To give a better idea of real-world classification performance, we plot Top-5 Accuracy on our 640-way classification task for off-the-shelf “vanilla” LLMs pre-trained on domain general web text and LLMs with continued pre-training on customer support transcripts. We also compare against our previous pre-trained BERT model [9] that we use in multiple deployed customer support applications. We find we are able to increase classification performance over BERT by approximately 10% by exploiting scaling laws.
Deployment in an Online Customer Support Application
We deploy our classifiers by first exporting to ONNX followed by optimization using TensorRT on an NVIDIA A10G GPU. This deployment pipeline required solving a few technical problems:
- ONNX correctness: We pool over the right-most token in each input sequence, and so need to find the first unpadded index in a batch. ONNX does not support “advanced indexing” where the index is represented as a negative offset from the end of each sequence in the input tensor, so we need to be careful to write our pooling code with this in mind or the result will be incorrect. Here is the implementation we use which handles both padded batches and cases where there is no padding token.
pooling_indices = torch.eq(input_ids, pad_token_id).int().argmax(-1) - 1 pooling_indices = sequence_lengths % input_ids.shape[-1] - TensorRT dynamic input shapes: TensorRT defaults to optimizing for static inputs with pre-defined shapes. In our previous BERT-based system [9], we simply padded to the maximum sequence length which was suboptimal for shorter inputs, but typically counterbalanced by the speedup from optimization. However, we found the relatively longer input context of the Pythia LLMs (2048 tokens) improved classification performance but at the cost of latency. TensorRT 10 includes a few parameters to support dynamic input shapes without requiring reoptimization.
- minShapes: Set this to the minimum batch size by minimum sequence length for each input tensor e.g.,
input_ids:1x1,attention_mask:1x1 - maxShapes: Set this to the maximum batch size by maximum sequence length for each input tensor e.g.,
input_ids:8x2048,attention_mask:8x2048 - optShapes: Set this to the shape that should perform optimally for each input tensor. It may be useful to estimate this from sample inputs e.g., the most frequent shape
- minShapes: Set this to the minimum batch size by minimum sequence length for each input tensor e.g.,
Average, P99, and max latencies for our deployment pipeline are shown in the table below.
| Requests/Sec | Pythia-410m | Pythia-1.4b | Pythia-2.8b |
|---|---|---|---|
| 1 | Avg: 14.29 P99: 30.72 Max: 32.37 |
Avg: 28.80 P99: 40.95 Max: 41.45 |
Avg: 45.92 P99: 70.66 Max: 72.08 |
| 2 | Avg: 13.97 P99: 28.90 Max: 29.58 |
Avg: 31.64 P99: 59.91 Max: 67.07 |
Avg: 51.42 P99: 111.43 Max: 118.84 |
| 5 | Avg: 13.66 P99: 26.21 Max: 33.85 |
Avg: 30.96 P99: 60.65 Max: 66.67 |
Avg: 52.72 P99: 121.27 Max: 149.56 |
| 10 | Avg: 14.05 P99: 31.84 Max: 59.33 |
Avg: 33.02 P99: 79.86 Max: 116.40 |
Avg: 63.89 P99: 183.26 Max: 222.36 |
| 20 | Avg: 15.03 P99: 34.55 Max: 46.92 |
Avg: 40.42 P99: 110.96 Max: 178.11 |
Avg: 122.38 P99: 371.90 Max: 482.43 |
Our deployed application receives each message sent during a customer support case and returns the Top-5 template responses from the set used during fine-tuning that a human-in-the-loop can further customize before sending to a customer. Importantly, these template responses are static content and therefore there is no chance of hallucination like there would be if directly generating the response using an LLM.
Our application aims to reduce the amount of time it takes a human customer support representative to select the appropriate template response. Below, we show the selection time difference for support cases solved using responses from our model compared to manual selection measured over a one year period. On average, we were able to reduce selection time by 7.38 seconds, which corresponds to a 3.56% total time reduction over the course of an entire support case.
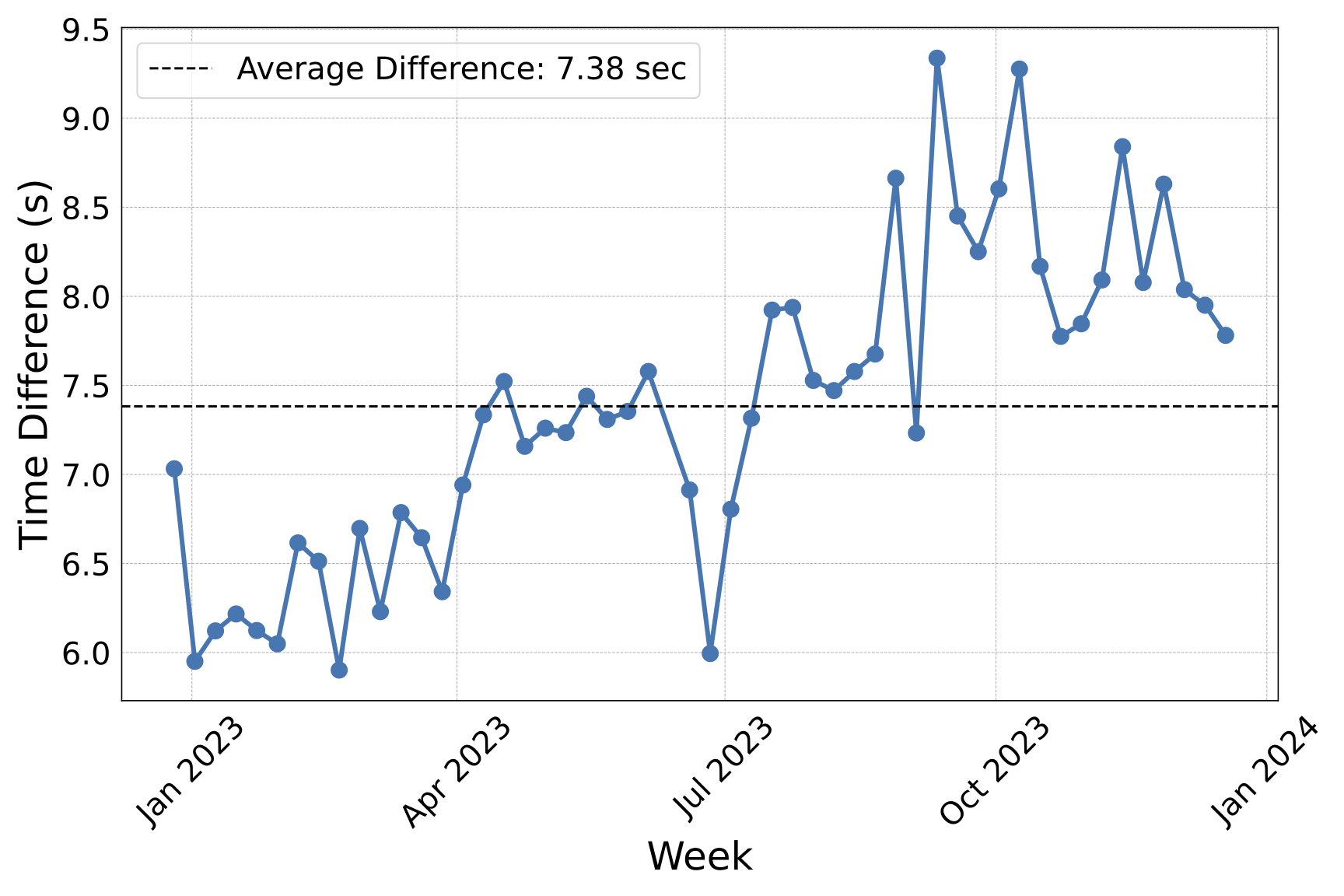
Because our system contains a human-in-the-loop performing customer support case work with selection time on the order of seconds, we favor smaller models like Pythia-410m as to not negatively impact their workflow. However, given the approximately linear scaling in classification accuracy we observed with continued pre-training, we have found we can improve classification performance over the lifetime of the system by periodically pre-training on additional customer support transcripts.
Summary
By turning LLMs into classifiers, we can leverage their unique scaling properties from increases in pre-training data and parameter count while preventing hallucinations altogether for applications requiring discrete decisions. For customer support applications where input context is long and the decision space can span hundreds or thousands of classes, our approach may be an attractive alternative to in-context learning using LLMs or the typical BERT-based classifier.
Acknowledgements
We thank Fatemeh Tahmasbi and Ming (Victor) Li for their contributions to the original work.
References
[1] Xu, Ziwei, Sanjay Jain, and Mohan Kankanhalli. “Hallucination is inevitable: An innate limitation of large language models.” arXiv preprint arXiv:2401.11817 (2024).
[2] Kaplan, Jared, et al. “Scaling laws for neural language models.” arXiv preprint arXiv:2001.08361 (2020).
[3] Li, Zongxi, et al. “Label supervised llama finetuning.” arXiv preprint arXiv:2310.01208 (2023).
[4] Touvron, Hugo, et al. “Llama: Open and efficient foundation language models.” arXiv preprint arXiv:2302.13971 (2023).
[5] Touvron, Hugo, et al. “Llama 2: Open foundation and fine-tuned chat models.” arXiv preprint arXiv:2307.09288 (2023).
[6] Devlin, Jacob. “Bert: Pre-training of deep bidirectional transformers for language understanding.” arXiv preprint arXiv:1810.04805 (2018).
[7] Warner, Benjamin, et al. “Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference.” arXiv preprint arXiv:2412.13663 (2024).
[8] Biderman, Stella, et al. “Pythia: A suite for analyzing large language models across training and scaling.” International Conference on Machine Learning. PMLR, (2023).
[9] Li, Victor, Wyatte, Dean. Improving customer support intent classification with additional language model pretraining (2023).
-
In general, we find this process generalizes to other LLM architectures and when pre-training from scratch. ↩