Merchant Recommendations 2.0 in Afterpay
Introduction
In this blog post, we’re excited to give you a behind-the-scenes look at how we revamped merchant recommendations in the Afterpay app, building on our previous work with Recommendations on Cash App. Over the years, the Afterpay recommendation system had grown complex and fragmented, relying on multiple models, heuristics, and manual processes across regions. Our journey to transform this system resulted in Merchant Recommendations 2.0, a unified, state-of-the-art deep learning framework powering recommendations across the Afterpay shop feed globally.
The Driving Force Behind Merchant Recommendations 2.0
The overhaul of our recommendation engine stems from the necessity to integrate, innovate, and improve our ML services continuously. By harmonizing our models into one robust framework, we address complexity, scalability, and performance limitations that previously hindered our ability to deliver seamless recommendations.
Consolidating and Simplifying the System
A key challenge we faced in upgrading the merchant recommendation system was the fragmentation of our approach. Over time, we had built separate models, heuristics, and manual rankings across multiple regions (US, UK, AU, NZ), each tailored to specific needs and product categories. While the separate model framework was customized for each use case and led to fine-tuned recommendations, it was harder to maintain and required significant effort for iterations. To overcome this, we consolidated 10 disparate models into a single, unified deep learning framework. By doing so, we eliminated redundancies, simplified the architecture, and significantly reduced the complexity of our system. The result is a more streamlined approach that not only boosts performance but also allows for quicker iterations and better alignment with business goals.
Enhancing Personalization and User Experience
The new model leverages 100x more data and advanced algorithms to better understand customer preferences, allowing us to deliver tailored recommendations that resonate with users. This enhancement has a direct positive impact on user discovery and transactions. By making recommendations more relevant, users can more easily find products and merchants that align with their tastes and needs even more than before, leading to a smoother, more engaging app experience. This not only helps users discover what they want but also streamlines their ability to transact seamlessly across the platform.
Unlocking Real-Time Recommendations
Previously, our system was limited to weekly batch offline inference, meaning recommendations were based on pre-computed data and could be stale. Now, we can deliver recommendations that dynamically adjust to real-time user behavior and current context, providing a more responsive and relevant experience.
Driving Business Impact and Operational Efficiency
Beyond direct business benefits, the new system improves operational efficiency. The simplification of our architecture has freed up resources, allowing our team to focus on more high-impact initiatives. Moreover, by avoiding additional infrastructure costs, we’ve ensured that our solution remains both cost-effective and scalable. These improvements have not only set the stage for future growth but also positioned us to respond to evolving product requirements and user needs more proactively.
Technical Details
Retrieval
Our existing offline retrieval logic tightly coupled with current production pipelines, relied on combining multiple sources like clicked merchants, lookalike retrieval, and collaborative filtering (CF) techniques to retrieve top k merchants from an inventory of over 40k for heavy ranking. While this personalization strategy is fine-grained and tailored to individual users, its complexity made it difficult to transition to online inference at reasonable costs without a major rewrite of our existing retrieval algorithms. We made a deliberate tradeoff and evaluated our current capabilities more holistically. Based on our findings and supporting data, we have taken a step back to streamline retrieval with a country-level approach, prioritizing simplicity and scalability. Combining various signals like historical engagement, transactions, GPV, and distinct user interaction, we retrieve up to 50 top merchants per category for each country using a weighted scoring method. These scores are updated daily in our feature store and fetched via a feature service, ensuring efficiency and consistency.
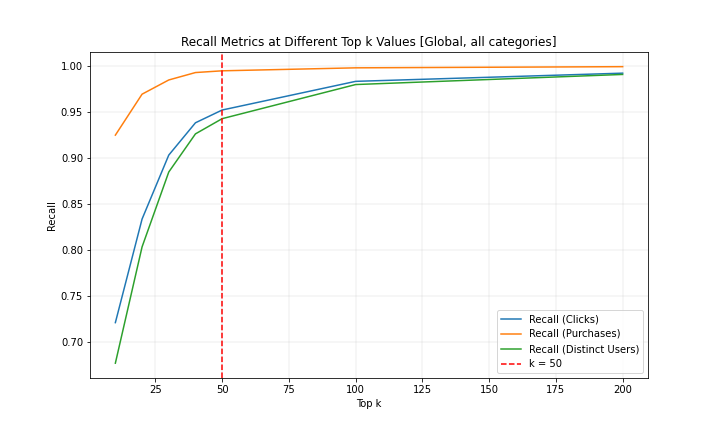
This simplified retrieval comes with trade-offs: while it may slightly reduce recall by focusing on top-performing merchants instead of a long-tail, it significantly lowers serving costs, improves interpretability, and enables faster iterations. Moreover, country-level retrieval offers a scalable solution across regions and categories, helping us establish a reliable baseline to build upon. Looking ahead, this approach lays the groundwork for reintroducing more complex, personalized techniques in a principled and iterative manner. Our goal is to iteratively refine retrieval strategies that balance efficiency with personalization, ensuring a seamless and engaging user experience while optimizing system performance.
Ranking
Model Objective
Historically, the absence of session-level impression logging on many of our surfaces has forced reliance on synthetic negatives for model training. These hard negatives, while useful, introduce biases by assuming unexposed items are true negatives, limiting the model’s ability to fully capture user intent within the conversion funnel.
To overcome these limitations, we propose shifting the model objective to predicting P(purchase|click). By conditioning on clicks, the model focuses on merchants that have already demonstrated user interest, enabling it to better predict purchases as a downstream event. This approach allows retrieval logic to prioritize merchants with a higher likelihood of engagement while aligning directly with the business goal of driving transactions. However, this change introduces challenges. First, model scores under the new objective are not directly comparable to baselines optimized for P(purchase|impression). Second, the inherent sparsity of purchase events could skew predictions toward frequent converters. To address these issues, we will leverage a robust training dataset spanning over two years of click and order data, representing billions of interactions. This large-scale dataset mitigates sparsity-induced biases and ensures sufficient coverage across diverse merchants and categories, preserving model generalizability.
Through offline evaluations, we compared models trained with different labeling strategies and negative sampling approaches to assess their effectiveness in capturing user behavior across the funnel. Specialized models, while excelling at optimizing for specific stages (e.g., clicks or purchases), struggled to generalize across multiple stages. Notably, we evaluated a P(purchase|click) model against a combined model that integrated predictions from P(click|impression) and P(purchase|click), with the latter relying on synthetic negatives to approximate unobserved interactions. Although the combined model aimed to holistically capture the user journey, its reliance on synthetic negatives introduced biases that hindered live performance. In contrast, the simpler P(purchase|click) model, trained solely on observed data, delivered superior performance across all critical business metrics in an online setting. These findings emphasize the importance of aligning model objectives with real-world data distributions and business priorities for robust and highly impactful outcomes.
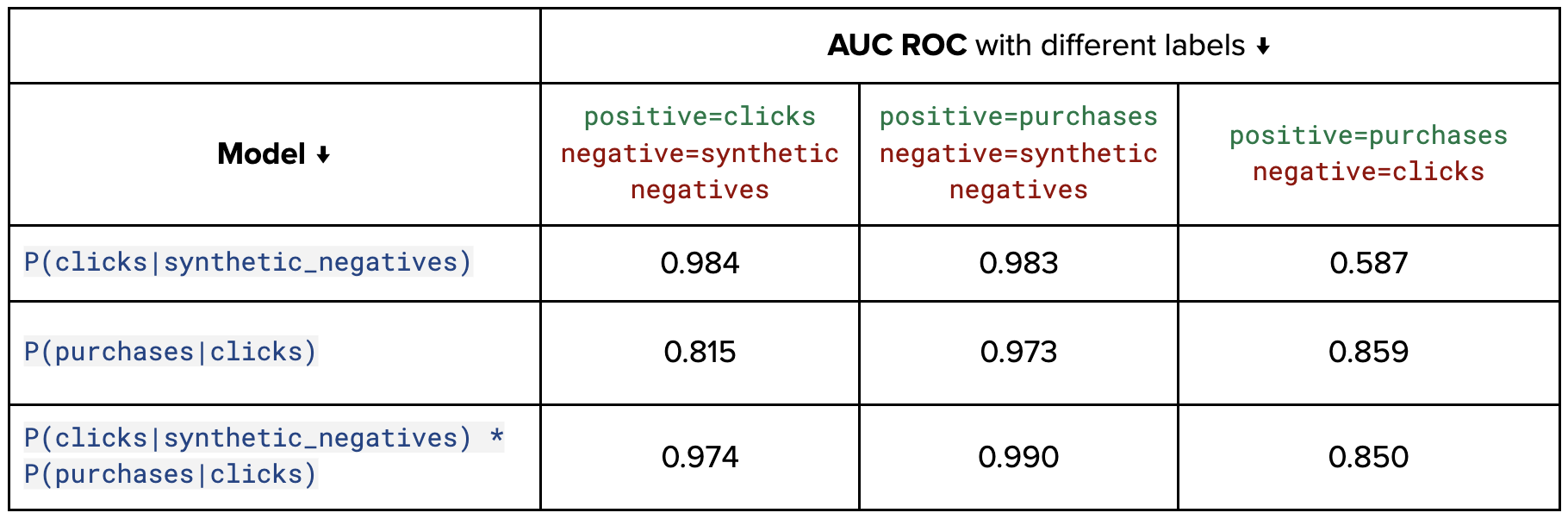
Offline Benchmarking and Baseline Comparison
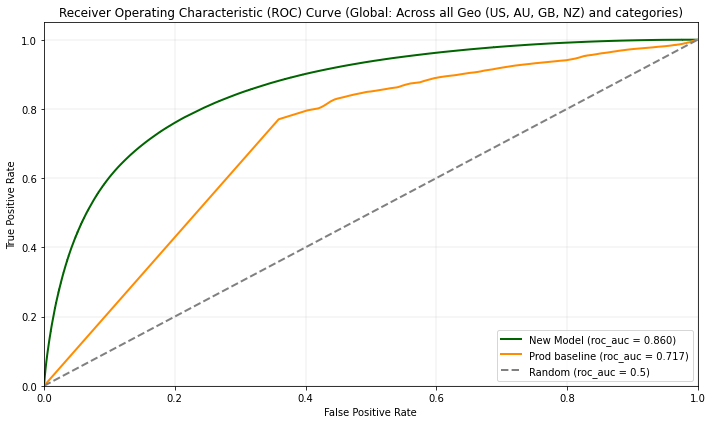
In our offline evaluation, we compared the performance of a global merchant recommendation model, developed using large amounts of clean ground truth data, with our existing country-specific production models. The global model demonstrated consistent improvement across all categories, with an average increase of approximately ~20% in AUC ROC. This significant enhancement indicates that the global model, trained on a broader and more comprehensive dataset, was able to capture patterns and relationships more effectively than the country-specific models, which were limited by their narrower focus.
The success of this evaluation highlights the importance of leveraging high-quality data and advanced algorithms to boost model performance. It also suggests that a more unified approach, utilizing global data and insights, has the potential to provide more accurate and relevant merchant recommendations. Given these results, we are encouraged by the possibilities of scaling this approach to offer improved, cross-border recommendations while reducing the complexity of maintaining separate models for each country.
Features
The input features are structured into four key categories, each tailored to encapsulate specific aspects of user-merchant interactions:
- Customer Metadata Features: Represent user-level information such as demographics, preferences, and other attributes, embedded into a n×d vector space.
- Merchant Metadata Features: Capture merchant-specific attributes, including categories, performance metrics, and metadata, similarly embedded as n×d vectors.
- Temporal Context Features: Include time-sensitive signals, such as user activity trends or seasonal patterns, time of day, day of week, etc, which are embedded to account for temporal dynamics.
- Time-Windowed Counter Features: Aggregate historical interactions combining various entities over predefined intervals (e.g., 7, 28, 84, and 364 days), providing both short-term and long-term context to enhance predictive power.
Model Architecture
Over the course of developing our recommendation system, we experimented with several model architectures to identify the best approach for balancing performance, scalability, and interpretability. Early explorations included simple feed-forward networks, which offered a strong baseline but struggled to capture complex feature interactions. We also tested transformer encoders, leveraging their ability to model sequential dependencies and attention-based feature interactions. While powerful, transformers proved computationally expensive and less interpretable in our high-dimensional, tabular data setup. Another promising approach was the Deep Learning Recommendation Model (DLRM), which uses dot-product interactions between embeddings to capture pairwise relationships. However, it fell short in capturing higher-order interactions critical for nuanced tasks like purchase prediction. After extensive experimentation, we adopted the Deep and Cross Networks v2 (DCNv2) architecture, which outperformed all other approaches across key metrics.
Deep and Cross Networks v2 (DCNv2)
DCNv2 combines the strengths of a cross network to explicitly model feature interactions and a deep network to learn complex, non-linear representations, offering the best trade-off between interpretability and predictive accuracy.
We found that DCNv2 was a strong fit for our use case for the following reasons:
- Explicit Feature Interactions: The cross network models interpretable feature interactions, critical for aligning predictions with business intuition.
- High-Order Patterns: The deep network captures complex, non-linear interactions, ensuring flexibility in modeling intricate relationships.
- Scalability and Efficiency: Compared to transformer encoders, DCNv2 is computationally lightweight, making it well-suited for production environments with high throughput demands.
- Robustness to Bias: Unlike DLRM, which relies on dot-product interactions that can amplify noise in sparse datasets, DCNv2 effectively balances explicit and implicit interactions.
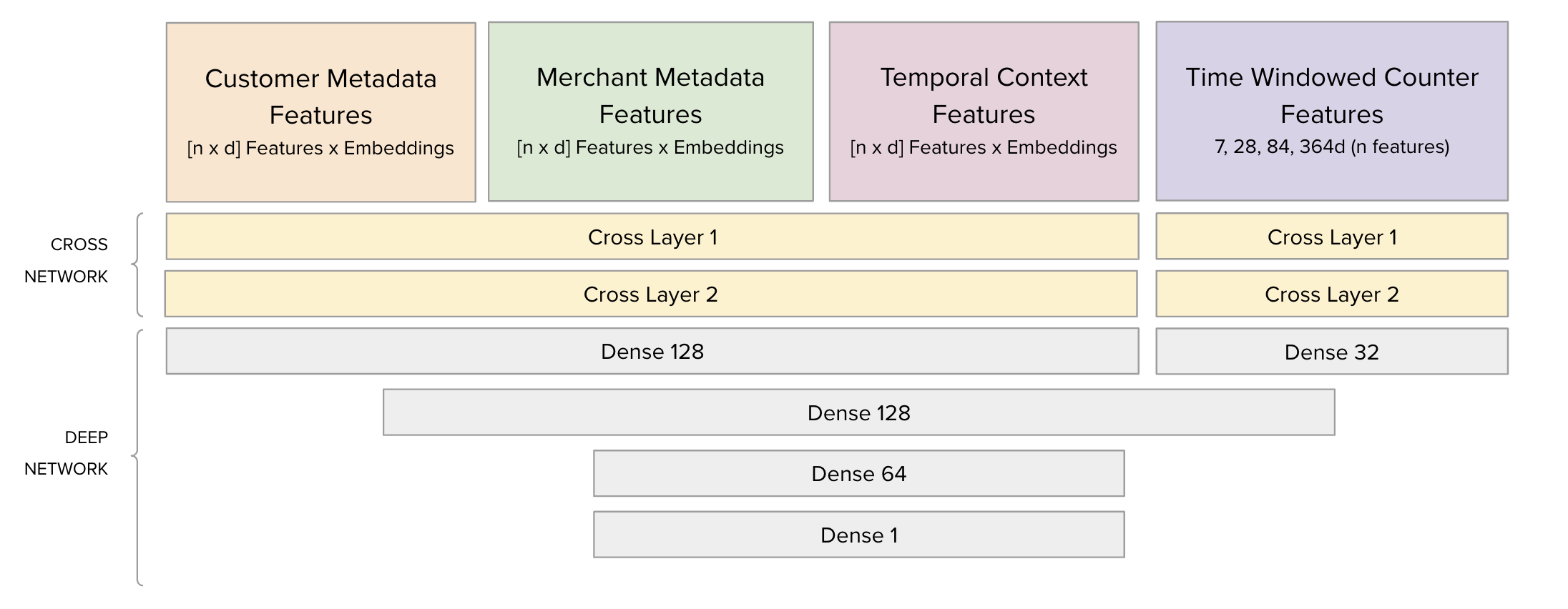
DCNv2 combines two primary components: the Cross Network and the Deep Network.
Cross Network
The cross network efficiently models explicit feature interactions by iteratively combining input features through cross terms:
- Cross Layer 1: Takes the raw input features and computes pairwise interactions. The output of this layer is: \( x_{l+1} = x_0 \cdot ({w_l}^T x_l) + b_l + x_l \). Here, \(x_0\) is the original input, \(x_l\) is the current layer’s output, and \(w_l\) and \(b_l\) are learnable parameters.
- Cross Layer 2: Builds on the first layer to capture higher-order interactions, enhancing the model’s ability to learn structured relationships.
This component is computationally efficient and ensures that interpretable, low-order interactions are explicitly modeled.
Deep Network
The deep network complements the cross network by capturing high-order, non-linear patterns:
- Dense Layer (128 units): Applies non-linear activation (ReLU) to transform the input features.
- Dense Layer (64 units): Further refines these transformations, reducing dimensionality while preserving important patterns.
- Dense Layer (1 unit): Outputs the final scalar prediction, which represents the probability of the target event (e.g., purchase).
Regularization techniques such as dropout and batch normalization are applied to ensure generalization and stabilize model training. Furthermore, we maintain a simple architecture to avoid overfitting, ensuring the model generalizes well to unseen data.
Model Training and Serving Infrastructure
Training deep learning models presents immense potential for improving performance, thanks to their flexibility in modeling complex relationships. However, this flexibility also introduces significant challenges, particularly in managing the numerous parameters that need to be optimized. To ensure that we fully capitalize on the capabilities of these models, we have focused on systematic training and evaluation processes. Over the past year, our efforts have centered on building a well-structured shared codebase (also powers merchant recommendations on Cash App), which houses rigorously reviewed code to enable efficient model training. This investment has allowed us to approach model development with greater confidence and efficiency, ensuring that we are moving closer to real-world performance benchmarks. Continuous updates to our shared codebase further enhance our ability to build high-performing models while maintaining a strong foundation for future innovation.
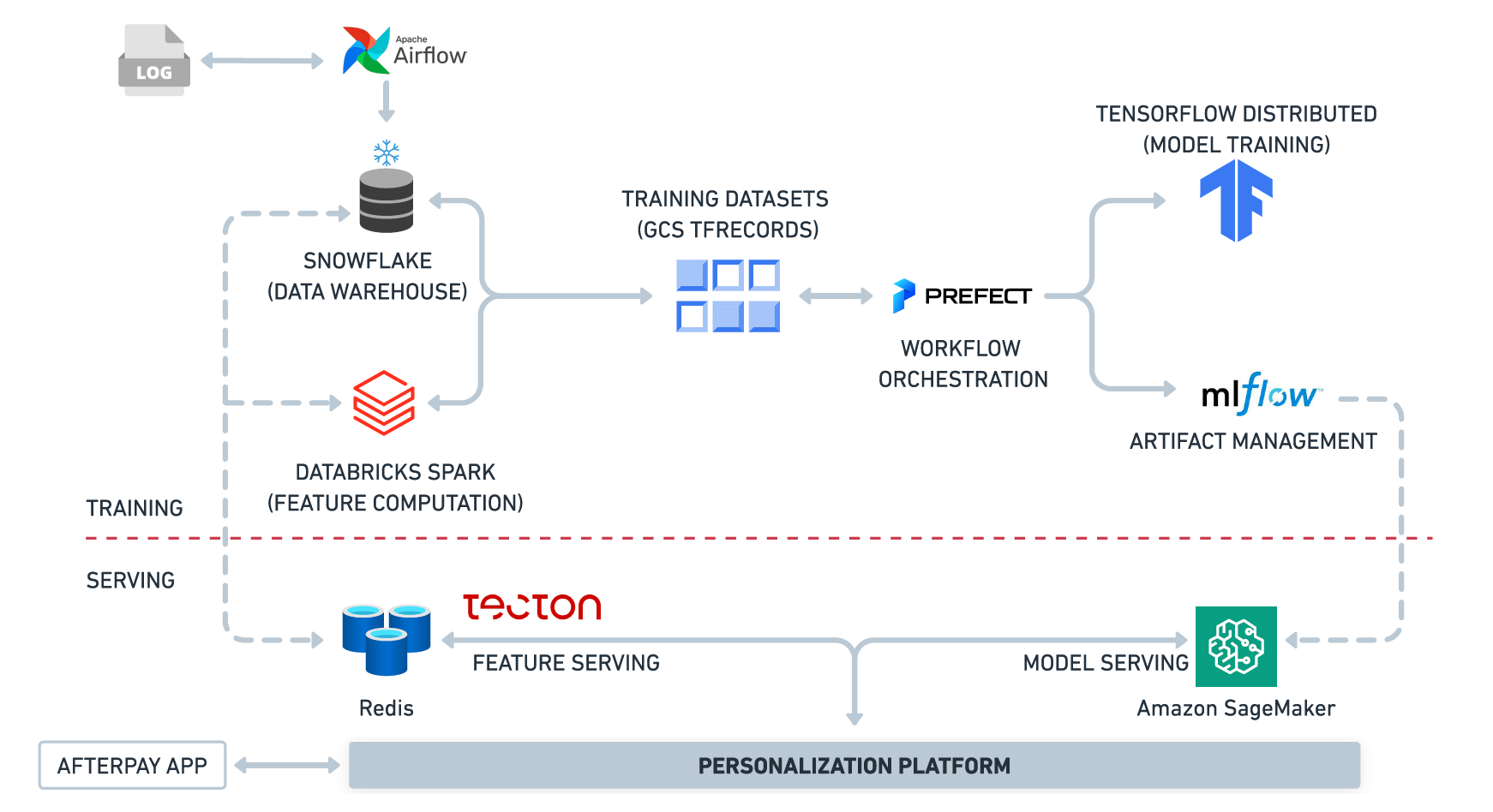
To support this effort, we have made significant strides in integrating a suite of advanced tools for distributed training, logging, and artifact management. Tools like Vertex AI are utilized for distributed training, enabling us to efficiently scale our workloads and handle large datasets. MLflow is integrated for comprehensive tracking of metrics and artifact management, providing insights into model performance throughout the training process. We utilize platforms like Databricks Lakehouse for offline feature computation and Snowflake for raw data storage. For model serving, we leverage Sagemaker and internal model hosting infrastructure to deploy models in a scalable and cost-effective manner. Additionally, we rely on Prefect for job scheduling and Tecton for online feature serving, ensuring that our models can efficiently serve predictions in production environments. These tools not only facilitate training and serving but also ensure the process is reproducible and well-documented, enhancing both collaboration and performance consistency across teams.
Conclusion
In conclusion, the revamp of Afterpay’s merchant recommendation system is more than just a technical upgrade — it is a strategic leap forward. By unifying a fragmented landscape of models and processes into a single cutting-edge deep learning framework, we’ve unlocked significant improvements across key business metrics while dramatically enhancing the user experience. With a solid foundation in place, Afterpay’s recommendations are primed to evolve, becoming smarter and more efficient with each update. This highly impactful launch was made possible through close collaboration and support from the strong product leadership, several backend and infrastructure teams, and the Product Data Science team, alongside the Block Personalization ML team. Thanks for reading!