Using Natural Language Processing to Reduce Account Takeovers
According to the LexisNexis 2021 True Cost of Fraud Study1, roughly one-third of financial services companies surveyed responded that account login was the part of the customer journey most susceptible to fraud. When fraud occurs at the account login level, it’s called an account takeover, or ATO.
Here at Cash App, we’re always working to improve our algorithms, systems, and processes to help keep our customers safe. In this post, I’ll share:
- how our team uses natural language processing models to help detect ATOs and secure customer accounts
- what this approach says about the importance of understanding the quality of training labels and data processing
- how our team has expanded on this methodology through semi-supervised methods to further protect our customers
Account Takeover Data is Messy
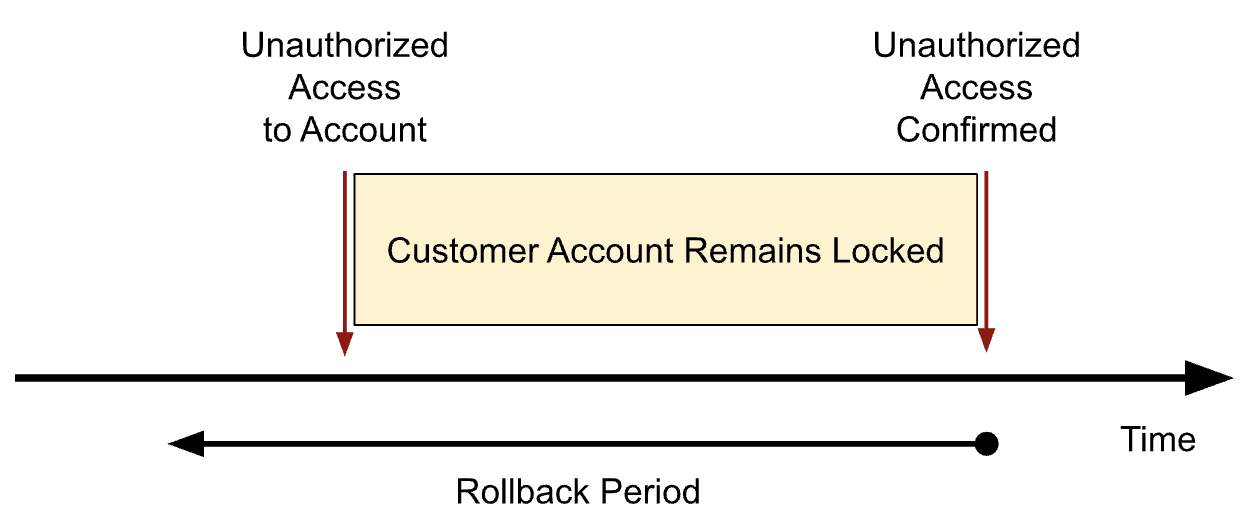
To protect our customers in the unfortunate event of an ATO, we preemptively lock accounts when unauthorized access is suspected, which safeguards customer assets and prevents fraudsters from taking further action. If an account review confirms unauthorized access has occurred, one way to secure the account is to perform a rollback, which rolls back, or resets, many account attributes that could have been modified by a fraudster, such as adding a phone number they control. As a result, this defines a rollback period over which a customer’s account was accessed by the unauthorized fraudster. In the ideal case, the rollback period can be conceptualized as below.
The other thing we review during a rollback period are transactions that took place. For a number of reasons, it is non-trivial to determine which particular transactions in a rollback period were unauthorized. If the device history on an account is complicated, or the fraudster is sophisticated in masking their access and usage patterns, then it may not only be difficult to identify unauthorized transactions, but also to systematically map them in a way that is available to our models for training. For example, fraudsters may attempt to obfuscate their unauthorized access by using multiple devices through multiple logins over an extended period of time. This increases the complexity of programmatically identifying unauthorized logins and transactions from fraudster devices and characteristics. Additionally, if the customer did not notice the unauthorized access immediately, it is possible that they would continue to use their account as normal to make transactions, leading to both legitimate and unauthorized transactions in a rollback period.
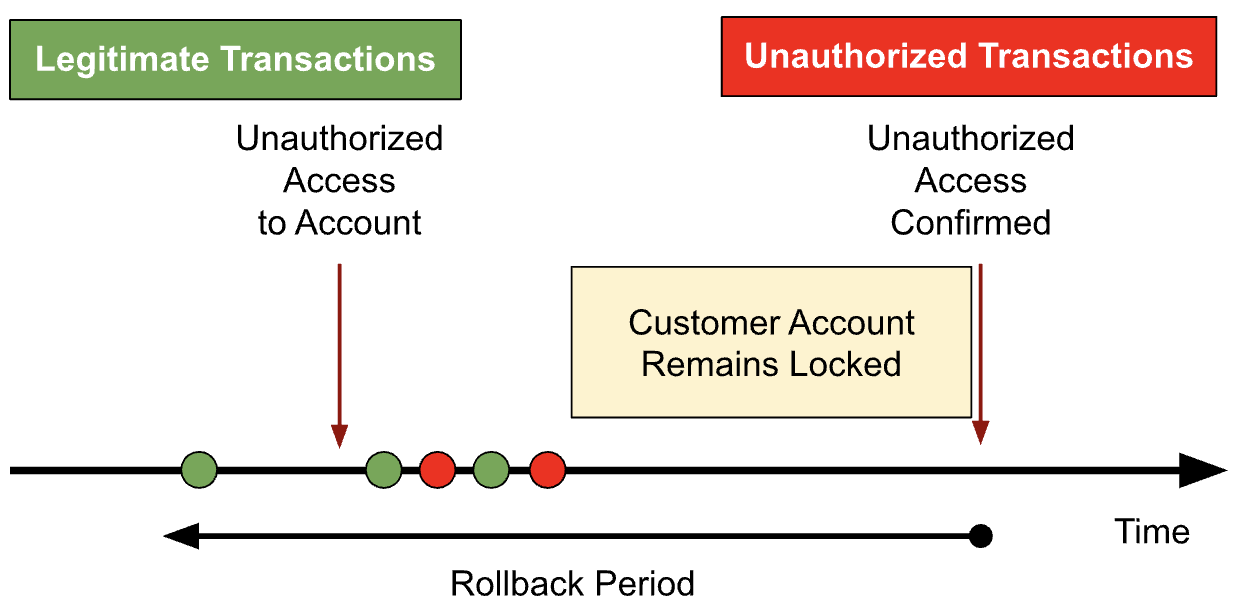
Without precise identification of unauthorized transactions, it is difficult to train ML models. If we have a mix of legitimate and unauthorized transactions in the positive labels and negative labels of our training data, then our models will have a more difficult time learning distinctive patterns; if we have noisy data going in, we will likely get noisy predictions out.
Customer Input Helps, but is also Messy
This begs the question: if unauthorized activity is happening on a customer’s account, why don’t we just get the customers to tell us which transactions are unauthorized? While logically tractable, this is also non-trivial in practice. First, our ML systems are sophisticated enough to detect unauthorized access before a customer, and often we resolve the lock on an account without any customer interaction. Second, in cases where we prevent unauthorized transactions through our risk ecosystem, customers likely would not know about the transactions to report them. Third, even when customers do reach out, they may not always be able to provide this information; customers may sometimes struggle to recall exactly which transactions are unauthorized, especially if they don’t notice them immediately.
However, when this data is available, it is extremely valuable2. Having a customer report which transactions were unauthorized in an ATO situation still provides gold-standard identification of unauthorized transactions. But, by examining how much data we would lose if we only look at transactions that customers do report, we find that we would be missing out on a vast majority of data. Furthermore, on top of the substantial sheer loss of volume of potential training data, the data we have after is relatively messy.
Natural Language Processing Helps us Cut Through the Noise
So how can we cut through the noise of rollback periods and noisy customer input? One of our solutions which we highlight and explain here is that we use natural language processing. Namely, when customers tag transactions, they also provide free-form text, which we can use to further identify whether the tagged transactions are unauthorized or not.
But wait—do we really need the large language models of lore to improve our model performance? Might a simple keyword matching heuristic work just as well? We had the same initial thoughts as well, and certainly there are benefits to using a simpler approach. A heuristic-based approach would allow for a quicker iteration cycle, less maintenance overhead, cheaper model training, etc.
So to test the heuristic hypothesis and to estimate the potential lift from using a natural language processing approach to cleaning our labels, we trained three tree-based models each with different positive label sets and the same number of random negative labels:
- A heuristic cleaned model, where the positive labels were reported payment transactions in an ATO rollback period where the free-form text contained the phrases, “hack,” “stole,” “not authorize,” “unauthorize,” or “not send.” These phrases define the heuristic we used to clean the full set of potential positive labels. If a reported transaction contained one of the phrases, we included it in our training data; otherwise, we excluded it.
- A BERT cleaned model, where the positive labels were reported payment transactions in an ATO rollback period most likely to be unauthorized transactions as determined by a BERT3 model. The BERT model itself was fine-tuned on hand-labeled data to detect the language of unauthorized transactions—prior reported payment transactions were reviewed and labeled as related to an ATO or not, and our BERT model was refined to distinguish that language and find common words and phrases that indicated that an unauthorized transaction was part of an ATO. We then used the fine-tuned BERT model in the same way as the heuristic; any reported payment transaction that the BERT model determined was unauthorized would then be included in our training data, and others would not.
- A messy model, where the positive labels were the full set of reported payment transactions in an ATO rollback period. We did not perform any data cleaning for the training data for this model.
In order to maintain the comparison, we kept the amount of training data the same between the heuristic cleaned and BERT cleaned models; only the makeup of the training examples, particularly those that were presumably ATO’d transactions, differed. In fact, 86% of the training data was exactly the same between the models, suggesting that even a modest change in the makeup of training data when the data is higher quality can make a significant difference in downstream performance. Furthermore, both of these models had 30% fewer training examples than the messy model. These differences highlight the importance of data quality and processing in model training, and as we will see in the results, more data is not always better.
To compare the performance of our models, we let the three models score the same transactions on our platform over the course of two weeks. We then took the top N scored transactions per model in that period, and estimated the area under the precision-recall curve (AUCPR) for this subset of transactions, using rolled back accounts as our source of truth4. A higher AUCPR indicates that our model would have been able to protect more customer accounts with fewer false positives, and therefore is a more performant model.
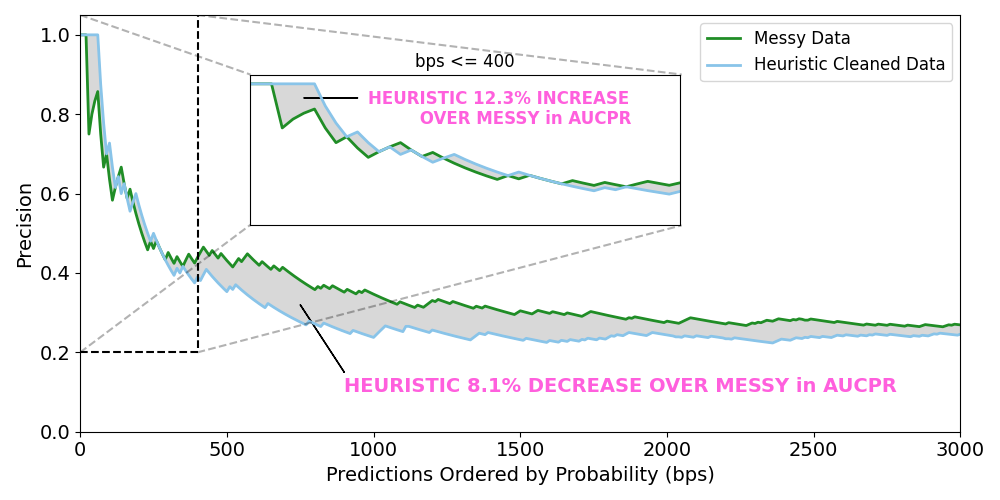
What we found, shown in Figure 1, is that using a heuristic to clean the positive labels in our model does improve performance (+12.3%), but only for the top predicted portion of transactions. Beyond a certain point, 400 bps of the subset of transactions in our analysis here, actually having more messy data rather than less cleaner data does better. This suggests that our heuristic cleaned model is overfitting on certain kinds of unauthorized transactions, and having more unauthorized transactions, even if some are mis-labeled, helps our model learn more general features of ATO unauthorized transactions.
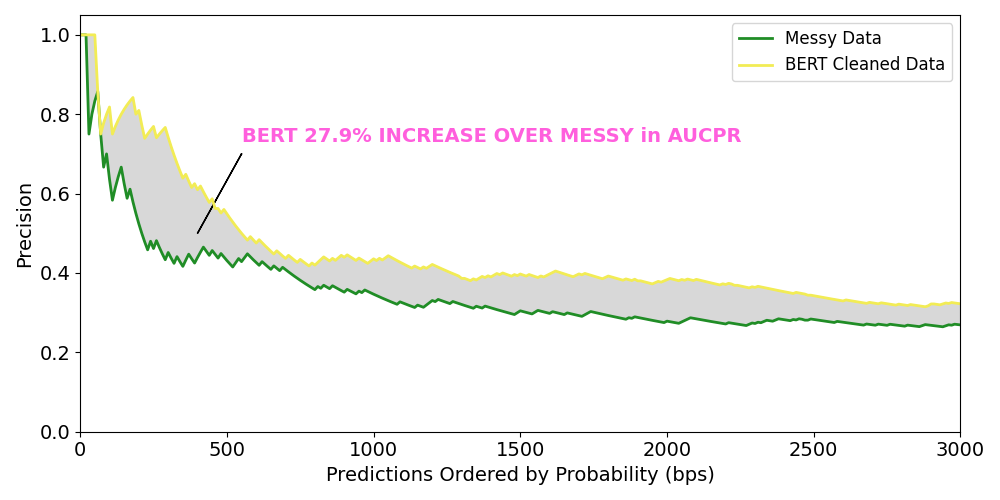
However, when we compare the BERT cleaned model with the full data model in Figure 2, we find performance gains throughout the whole set of our subset of transactions, and an overall lift of 27.9% in AUCPR. This is a significant lift considering the BERT cleaned model had 30% fewer positive labels, and suggests that taking the time to improve the quality of training labels pays off in model performance.
While this methodology already helps us protect our customers, there are also natural extensions that we are exploring. We can use a different natural language processing model; we can do some pre-training of our natural language processing model; we can add custom tokens to the tokenizer5; we can train on tabular features as well as text features; or we could use a BERT model with more parameters. We rely on our modelers’ experience to know when and how to apply these extensions to maintain an optimal modeling ecosystem.
Moreover, we have been able to extend not only this approach, but the general framework of semi-supervised approaches to model training in other parts of our modeling ecosystem. What we have done here is use one model (BERT) to generate a precise set of labels for another model (tree-based model). In many scenarios, we have a significant amount of unlabeled data; in this case, that may be ATO unauthorized transactions that are simply not reported by customers. By starting with our precise set of labels, we can then use other approaches to find similar unlabeled transactions and expand our set of positive labels, improving our models not only with cleaner labels, but with more labels as well. More clean data > clean data.
Summary
To sum things up, in this post we’ve walked through a short case study in how we have used natural language processing to improve our ability to protect our customers from ATOs. We demonstrated that more data does not always produce a better model, and hope to challenge ourselves and others to continue to think deeply on the data generating processes around our labels and training data. We hope that as we continue to use our machines to help us understand and protect our customers as much as possible, we can inspire others to do the same.
Footnotes
-
LexisNexis Risk Solutions, Inc. (2022). LexisNexis® True Cost of Fraud™ 2021 Study - Financial Services and Lending Report. Retrieved August 22, 2022, from https://risk.lexisnexis.com/insights-resources/research/us-ca-true-cost-of-fraud-study#financialservices. ↩
-
Because this data may contain sensitive information, we take the utmost care to protect our customers’ privacy and security. Our data storage and usage policies are guided by our security team and involve a number of safeguards to protect various degrees of personally identifiable information. ↩
-
Devlin, J., Chang, M. -W., Lee, K., and Toutanova, K. (2018 October 11). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. Retrieved September 1, 2022 from the arXiv database. BERT models use a deep learning neural network architecture to look at words in their context to understand meaning. ↩
-
Given some complexities of our ecosystem, this is merely a proxy for the real performance of these models. ↩
-
We have in fact added emojis into our BERT tokenizer here, and in other areas have found significant improvement as a result. ↩