Real-time Merchant Recommendations on Cash App with Deep Learning
Introduction
Cash App thrives on its mission to make customers’ money go further by helping them discover meaningful savings, inspiring them, and connecting them with merchants. This provides a massive opportunity for us to deliver enhanced customer satisfaction and engagement, ultimately leading to better outcomes for the customer, merchants, and Cash App. With that goal, we’re building cutting-edge recommendation models for our customers for several use cases including the discovery of best offers with merchants that users care about. In this blog post, we’ll discuss our journey of upgrading our machine learning capabilities and progressively deploying cutting-edge deep learning recommendation models, all while navigating the challenging shift from batch offline processing to real-time online inference for recommendations systems at Cash App.
Background
The initial merchant recommendation systems at Cash App were developed using our in-house powerful feature prototyping tool Blizzard, which facilitated the rapid model development by leveraging existing features. Although this allowed us to establish a robust baseline and demonstrate tangible impact on our business by swiftly rolling out our initial models at an accelerated pace, it provided us several opportunities for making major improvements to our ML capabilities both on the model and our training and serving infrastructure for a longer horizon.
Model
Our production baseline was an XGBoost model (Extreme Gradient Boosting), a machine learning algorithm rooted in Gradient Boosting Decision Trees (GBDT), trained on several hundred carefully crafted features. GBDT models are formidable tools for specific tasks, especially those involving structured data and a need for interpretability. Despite the robust foundation, we encountered limitations inherent to GBDT models, including their constraints in capturing intricate patterns and achieving strong personalization, as well as their dependence on manual feature engineering. This spurred our exploration of deep learning as a means to bypass these constraints, elevating our previous limitations to new standards, offering ample room for future improvements, and positioning us for long-term success.
Infrastructure
Our initial recommendation systems were designed for batch offline inference, involving the daily computation of model predictions, and their subsequent storage in our online data store to provide recommendations on Cash App the following day. These daily batch offline processes generated a substantial volume of predictions stored in our online serving data stores, even though only a fraction of users accessed these recommendations on a daily basis. This inefficiency in computation led to linearly increasing compute and storage costs. As the Cash App inventory and user base expanded, the demand for recommendation ranking also grew, resulting in significant delays on a larger scale and occasional failures in batch offline inference jobs. Furthermore, our infrastructure constraints prevented the model from harnessing essential contextual information, such as temporal features (time of day, day of the week, etc.). This contextual information plays a pivotal role in guaranteeing the relevance and timeliness of model predictions. This inspired us to revisit our strategy and devise a plan for transitioning into the realm of real-time online model inference.
Laying the Foundation
First Principles
The goal of our recommendation system is to be highly personalized for customers while keeping recommendations fresh and tailored to our customer’s needs.
- Offline / Online Activity: Our modeling approach is driven by the themes of offline and online brand affinity, leveraging our deep understanding of customers’ brand preferences in both realms to enhance our personalization engine.
- Brand Understanding: By internalizing the traits of different merchant brands, we can identify parallel trends and better cater to customer interests, making brand understanding a significant driving force behind our framework.
- Capturing Subtle Customer Preferences: Capturing our customers’ unique, subtle preferences is key to tailoring the most fitting offerings, at the right time.
Unified Data Sources
We built a unified data source that would serve as the bedrock for training our machine learning models, aiming to accomplish several critical objectives. We successfully unified the diverse data sources bringing together customer and merchant interactions, irrespective of whether the transactions occurred online, in-app, or offline. This consolidation enabled us to establish an extensible and versatile design, one that remains agnostic to specific product surfaces, providing the flexibility to seamlessly incorporate additional data sources.
Features Strategy
Our initial models used existing features developed using our in-house powerful feature prototyping tool Blizzard. As part of our strategy to prepare for the transition to real-time, online inference, we opted for a simplified feature approach. Rather than exporting all the previous features available for online serving from Blizzard, a feature system which had made a deliberate set of tradeoffs around non-massive scale and non-real-time evaluation, we selected a small list of <10 features for our initial feature setup. These features represent only the most important static customer and merchant metadata, along with contextual information. Notably, we omitted time-windowed aggregation features. This strategic choice was made to optimize cost-efficiency, enhance observability, and mitigate the computational burden associated with feature aggregations when dealing with large data volumes during inference. The simplified feature configuration also streamlined model debugging, alleviated training and inference discrepancies, and offered a degree of model explainability. These improvements made it easier for us to build our infrastructure for real-time inference while incrementally shipping value.
Model Iterations: An Evolutionary Journey
Over the past year, we’ve evolved the model substantially, growing our initial Basic Deep Learning model with consistent, incremental improvements. Each iteration brought new insights and improvements to business metrics while substantially improving customer engagement.
V1: Basic Deep Learning Model
In our journey to implement our inaugural deep learning model for personalization and merchant recommendation within Cash App, we embarked with a set of intriguing questions:
- Could a straightforward deep learning model, armed with an exceedingly minimalist feature set, surpass the performance of an XGBoost model trained with several hundred meticulously crafted features?
- Was it possible to adeptly capture and learn intricate user preferences and the nuanced representations of merchants, implicitly modeled through embeddings created from scratch during the training process?
- And, most importantly, could we drive significant cost savings by deploying this simplified deep learning model for online inference, thereby bypassing the dependence on costly daily batch inference operations?
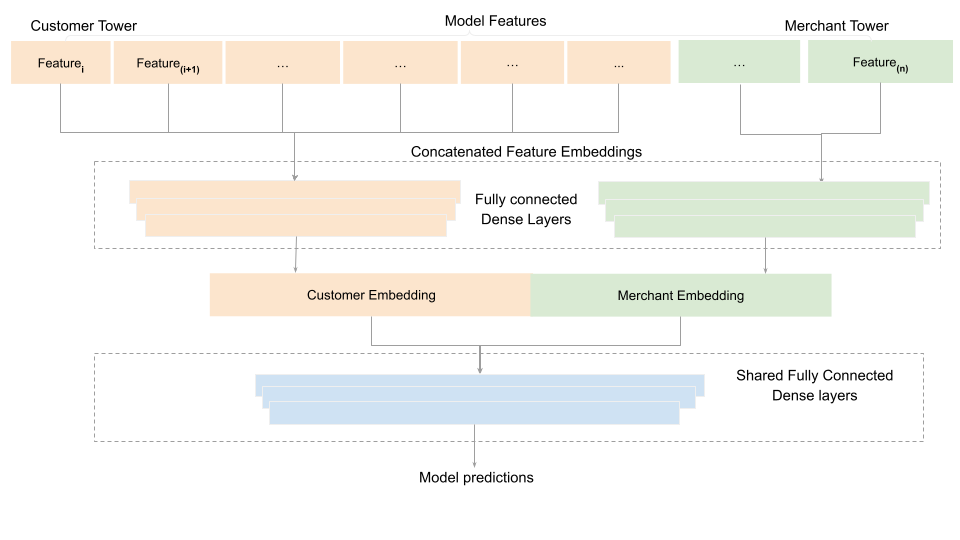
As shown above, the basic model architecture involved three main components: a customer tower (responsible for capturing user preferences leveraging categorical information from basic demographic and temporal features), a merchant tower (merchant metadata features) and shared dense layers that stitched together the two towers to finally learn to predict the likelihood of a positive customer interaction P(click or transaction) with a merchant. The model mainly consisted of stacked dense fully connected layers on top of concatenated embedding layers. The network also comprised additional layers for dropout and batch normalization which were included to prevent overfitting, improve training speed and stability by using large batch sizes and higher learning rates. As we launched the online A/B experiment, our expectations were conservatively set at achieving parity with our previous best XGBoost model, which had several hundred hand-tuned features. To our delight, the deep learning model, equipped with just eight features, outperformed the previous production model. This resulted in small improvements in user engagement and business metrics (a low X% increase), all while drastically reducing our annual infrastructure costs by over 60%. With this, we debuted our first deep learning production model for merchant recommendation on Cash App, running on real-time inference infrastructure serving production traffic.
V2: Incorporating the Transformer Encoder
Deploying the initial model online provided us with valuable insights into the strengths and weaknesses of the basic deep learning model. We noticed its proficiency in personalizing recommendations for users with dedicated embeddings but encountered challenges with new users and merchants. To address this, we implemented feature hashing for out-of-vocabulary (OOV) tokens and expanded the size of our embedding matrices to accommodate more customers, thereby enhancing the model’s performance for cold start scenarios. We also integrated finer grain merchant categorization in our models to allow for improvement in performance of existing and newly onboarded merchants.
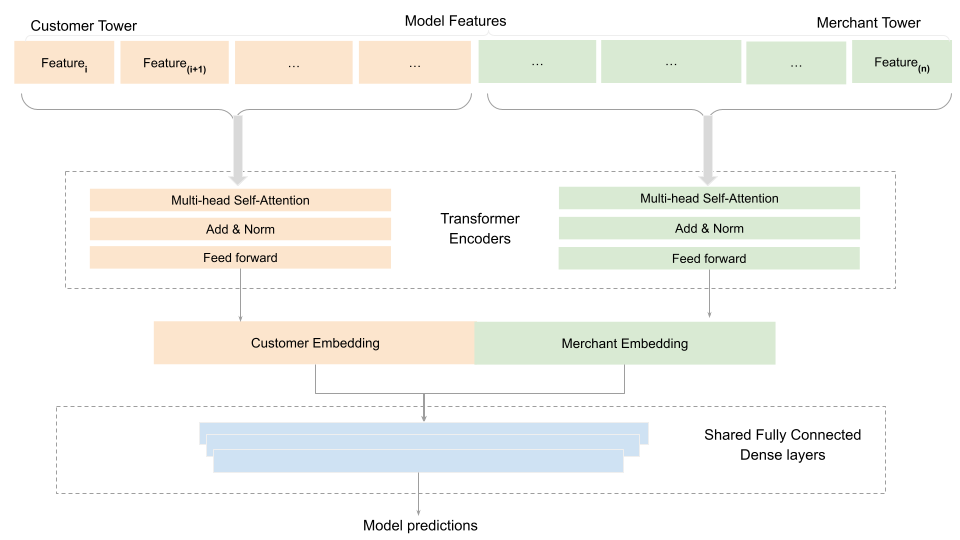
Furthermore, we recognized that the fully connected dense layers struggled to capture inherent data dependencies and were resource-intensive. In response, we replaced them with the Transformer encoder architecture as shown above, which has gained prominence, especially in Large Language Models (LLMs). Transformers can embed both user and item information in a shared latent space, facilitating a more comprehensive understanding of user-item relationships—a valuable asset in recommendation systems where interactions involve a mix of user profiles and item attributes. Through A/B testing, this revised model demonstrated low double-digit improvements in key user engagement and business metrics on important segments. The incorporation of Transformer encoders in our recommendation model has proven promising, addressing challenges in understanding nuanced user preferences and providing more effective recommendations in diverse and dynamic contexts.
V3: Integrating Time-Windowed Aggregated Counters and Last-N List Features
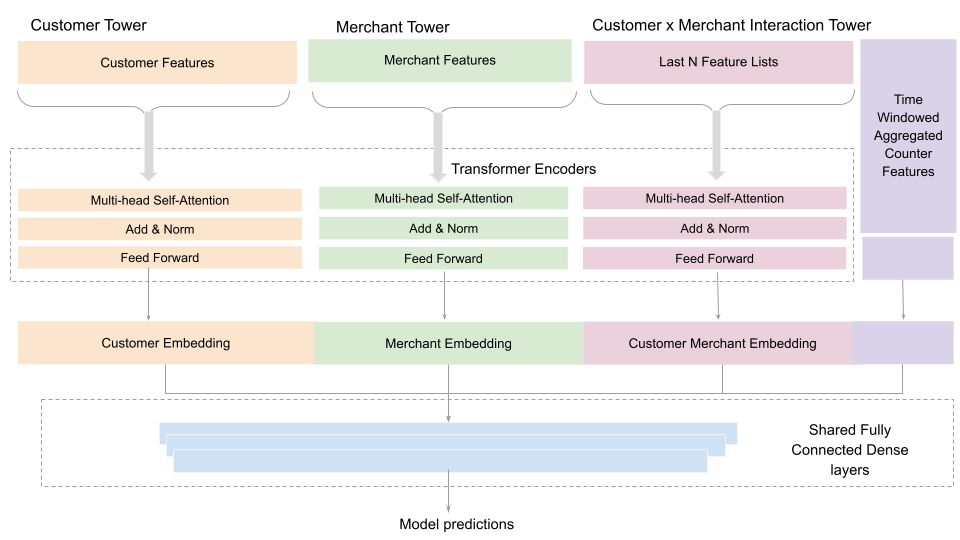
Our primary objective for the latest model iteration was to enhance the model’s adaptability to evolving user preferences and current trends among popular merchants which was lacking in the previous iterations of the models. With the groundwork of integrating the online feature store and enabling real-time inference already in place, our focus shifted to refining the model’s feature set. We introduced novel features, such as various time-windowed aggregated features at multiple levels (customer, merchant, customer-merchant pairs, etc.), including the lists of most recent merchants and merchant categories that the customer engaged with. These additions provided the model with more explicit signals to learn from, enabling it to offer dynamic, user-sensitive recommendations that stay current, curated, and highly relevant to Cash App users. We continue to iterate and test more improvements to our model architectures (Transformers, DCN: deep and cross networks, etc), features, and infrastructure which have consistently shown improvements in user experiences and positive impacts on our business.
Limitations
While deep learning can be a powerful tool for recommendation and personalization, it comes with certain limitations. Overcoming these challenges involved experience, experimentation, and close collaboration with cross-functional teams to bring in the required domain expertise.
Data Requirements
Deep learning models typically require large amounts of high quality data to generalize well. We found that inadequate and noisy data lead to poor model performance on certain segments of our online experiments. If you have a small dataset, it can be challenging to train deep neural networks effectively and it may be best to make use of traditional machine learning models instead.
Training Time and Resources
Training deep learning models can be computationally expensive and time-consuming, especially for large networks being trained on large volumes of data (like in our case). Some of our initial deep learning model prototypes required more than a week to finish training on a single, large machine. We invested a significant amount of time in the parallel development of our training infrastructure. This enabled us to run distributed model training efficiently and train models within reasonable amounts of time (~12 hours).
Interpretability
Deep learning models are often considered “black boxes.” They can be difficult to interpret, making it hard to explain why a particular recommendation was made. In some cases, simpler models may perform better with the added advantage of being easily interpretable. In order to make the results of our models at least partially interpretable, we developed proxy tools for model explainability. The explainability tool allowed the side-by-side comparison of model predictions with user’s historical interactions. This enabled us to contextualize model predictions, perform debugging, and indirectly interpret model predictions to ensure they were making sense.
Hyperparameter and Architecture Tuning
Through our offline and online model evaluations, we found that the choice of hyperparameters (e.g., learning rate, batch size, network architecture) can significantly impact deep learning model performance. Hyperparameter tuning is a critical but often time-consuming process. We used downstream model performance on offline metrics to inform our choices here with trial and error combined with some domain expertise. It’s also worth noting that it is important to avoid making models overly complex for certain recommendation tasks, which can lead to overfitting without proper regularization. Furthermore, we are also exploring automated hyperparameter optimization to streamline the process of finding the best model setups for our use cases.
Model Freshness
Model freshness is particularly critical in applications like recommendation systems, where the ability to recommend relevant content or products relies on current information. In our early online experiments, the model’s performance leveled off initially and then degraded over time leading to poor results. In addition to adding time-based aggregate features, we’re enhancing our training and serving infrastructure to support incremental model training to keep up with the latest trends, emerging patterns, and evolving user preferences.
Key Takeaways
Shipping state-of-the-art deep learning recommendation models, all while managing the complex transition from batch offline processing to real-time online inference for Cash App’s recommendation systems, entailed resolving numerous data, modeling, and infrastructure challenges. These initiatives yielded the following significant insights and more:
- Start simple: Occam’s razor
- Focus on data quality.
- Features: less is more (initially).
- Have solid offline metrics and quantitative evaluation in place to iterate and improve. Work closely with product and cross functional teams to also run qualitative evaluation and sanity checking model predictions.
- Make targeted improvements to address specific problems measurable offline and online. ex: improve performance for new customers, solving the merchant cold start problem, etc.
- Develop models with an engineering first mindset (feature serving, e2e latency, compute/memory, cost).
- Set reasonable expectations: shipping deep learning models in production takes time and coordinated effort.
- Deep learning is not a magic wand that automatically resolves all issues; instead, it introduces fresh challenges that, when tackled effectively, have the potential to yield significant business benefits over time.
Conclusion
Within this blog post, we’ve provided a glimpse into our iterative path and the transformation of our recommendation systems leveraging cutting-edge deep learning models and real-time online inference. We’ve made notable improvements to user engagement on Cash App while simultaneously achieving significant cost savings in infrastructure. More importantly, we have laid a strong foundation unlocking many more opportunities to further improve our offerings. None of these advancements would have been possible without the relentless work by our team of Machine Learning Modelers and Engineers, Data Scientists, and across-the-board cross-functional teams. The future is promising, and we’re poised to bring out even more sophisticated, personalized solutions to our Cash App users.
If you’re interested to learn more about the Machine Learning teams at Cash App or have any feedback on this post, contact me on Linkedin. Thanks for reading!